多进程介绍
在非 python 环境(C、Java、go)中,单核情况下,同时只能有一个任务执行,多核时可以支持多个线程同时执行。但是在 python 中,无论有多少核,同时只能执行一个线程。究其原因,这就是由于 GIL 的存在导致的。
GIL(全局解释器锁)
GIL 的全称是 Global Interpreter Lock (全局解释器锁),来源是 python 设计之初的考虑,为了数据安全所做的决定。某个线程想要执行,必须先拿到 GIL,我们可以把 GIL 看作是“通行证”,并且在一个 python 进程中,GIL 只有一个。拿不到通行证的线程,就不允许进入 CPU 执行。GIL 只在 cpython 中才有,因为 cpython 调用的是 c 语言的原生线程,所以他不能直接操作 cpu,只能利用 GIL 保证同一时间只能有一个线程拿到数据。而在 pypy 和 jpython 中是没有 GIL 的。
警告
python 3.12 版本之后,GIL 将成为可选的状态,但是以前的很多工具不目前还不支持无 GIL 模式,使用请慎重选择。
Python 多线程的工作过程
python 在使用多线程的时候,调用的是 c 语言的原生线程。
- 拿到公共数据
- 申请 gil
- python 解释器调用 os 原生线程
- os 操作 cpu 执行运算
- 当该线程执行时间到后,无论运算是否已经执行完,gil 都被要求释放
- 进而由其他进程重复上面的过程
- 等其他进程执行完后,又会切换到之前的线程(从他记录的上下文继续执行)整个过程是每个线程执行自己的运算,当执行时间到就进行切换(context switch)。
python 针对不同类型的代码执行效率也是不同的:
CPU 密集型代码 (各种循环处理、计算等等),在这种情况下,由于计算工作多,ticks 计数很快就会达到阈值,然后触发 GIL 的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以 python 下的多线程对 CPU 密集型代码并不友好。
IO 密集型代码 (文件处理、网络爬虫等涉及文件读写的操作),多线程能够有效提升效率 (单线程下有 IO 操作会进行 IO 等待,造成不必要的时间浪费,而开启多线程能在线程 A 等待时,自动切换到线程 B,可以不浪费 CPU 的资源,从而能提升程序执行效率) 。所以 python 的多线程对 IO 密集型代码比较友好。
使用建议?
python 下想要充分利用多核 CPU,就用多进程。因为每个进程有各自独立的 GIL,互不干扰,这样就可以真正意义上的并行执行,在 python 中,多进程的执行效率优于多线程 (仅仅针对多核 CPU 而言)。
GIL 在 python 中的版本差异:
在 python2.x 里,GIL 的释放逻辑是当前线程遇见
IO操作或者ticks计数达到100时进行释放。(ticks 可以看作是 python 自身的一个计数器,专门做用于 GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整)。而每次释放 GIL 锁,线程进行锁竞争、切换线程,会消耗资源。并且由于 GIL 锁存在,python 里一个进程永远只能同时执行一个线程 ( 拿到 GIL 的线程才能执行),这就是为什么在多核 CPU 上,python 的多线程效率并不高。在 python3.x 中,GIL 不使用 ticks 计数,改为使用计时器(执行时间达到阈值后,当前线程释放 GIL),这样对 CPU 密集型程序更加友好,但依然没有解决 GIL 导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。
从 python3.11 开始 python 解释器就开始解决 GIL 问题,预计在 python 3.12 版本就会被处理完。
预计 python 3.13 就会正式支持 GIL 成为可选择状态。
进程以及状态
当运行一个程序时,操作系统会创建一个进程。它会使用系统资源(CPU、内存和磁盘空间)和操作系统内核 中的数据结构(文件、网络连接、用量统计等)。进程之间是互相隔离的,即一个进程既无法访问其他进程的内容,也无法操作其他进程。
操作系统会跟踪所有正在运行的进程,给每个进程一小段运行时间,然后切换到其他进程,这样既可以做到公平又可以响应用户操作。你可以在图形界面中查看进程状态,在 Mac OS X 上可以使用活动监视器,在 Windows 上可以使用任务管理器。
一个程序的执行实例就是一个 进程 。每一个进程提供执行程序所需的所有资源。(进程本质上是资源的集合)
一个进程有一个虚拟的地址空间、可执行的代码、操作系统的接口、安全的上下文(记录启动该进程的用户和权限等等)、唯一的进程 ID、环境变量、优先级类、最小和最大的工作空间(内存空间),还要有至少一个线程。
每一个进程启动时都会最先产生一个线程,即主线程。然后主线程会再创建其他的子线程。
进程的状态
工作中,任务数往往大于 cpu 的核数,即一定有一些任务正在执行,而另外一些任务在等待 cpu 进行执行,因此导致了有了不同的状态
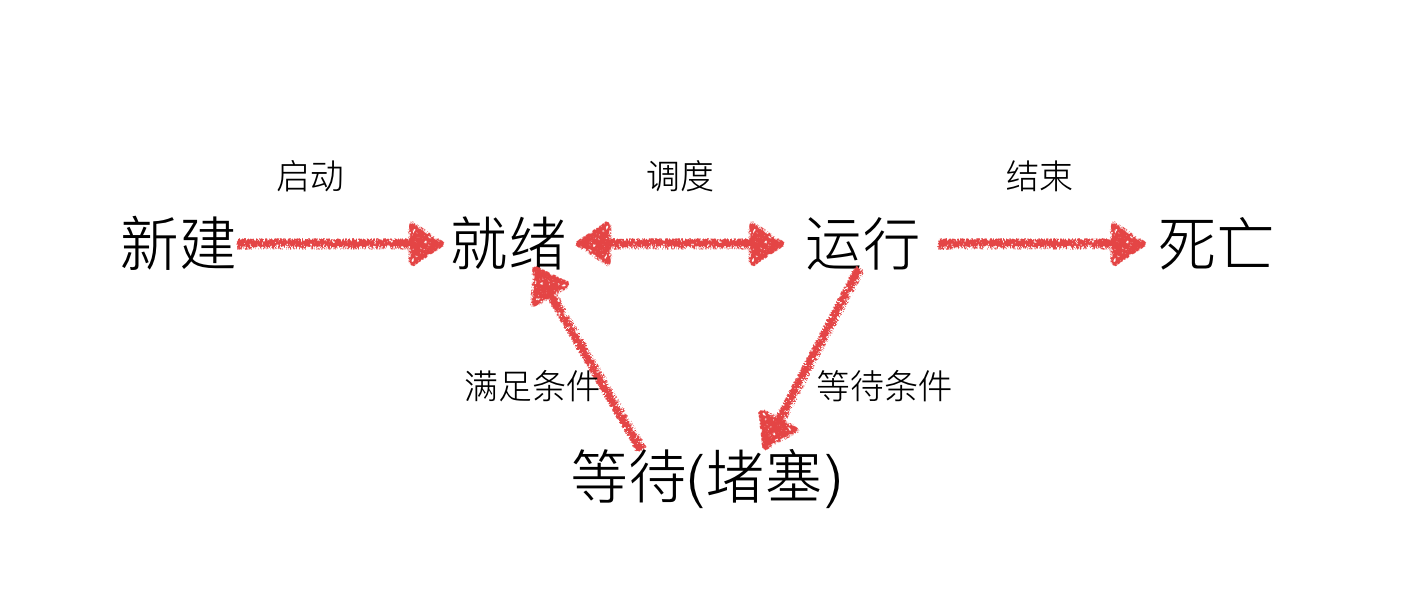
- 就绪态:运行的条件都已经满去,正在等在 cpu 执行
- 执行态:cpu 正在执行其功能
- 等待态:等待某些条件满足,例如一个程序 sleep 了,此时就处于等待态
而网络 IO 主要延时由:服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时决定。(一般为几十到几千毫秒,受环境干扰极大)
原文地址:点击这里
进程的创建
multiprocessing 是 Python 的标准模块,它既可以用来编写多进程,也可以用来编写多线程。multiprocessing 提供了一个 Process 类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
并行执行
# -*- coding: utf-8 -*-
import multiprocessing
import time
def upload():
print("开始上传文件...")
time.sleep(1)
print("完成上传文件...")
def download():
print("开始下载文件...")
time.sleep(1)
print("完成下载文件...")
def main():
multiprocessing.Process(target=upload).start()
multiprocessing.Process(target=download).start()
if __name__ == '__main__':
main()说明:
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个 Process 实例,用 start() 方法启动
进程对象
Process 介绍:
构造方法:
- Process([group [, target [, name [, args [, kwargs]]]]])
- group: 线程组,目前还没有实现,库引用中提示必须是 None;
- target: 要执行的方法;
- name: 进程名;
- args/kwargs: 要传入方法的参数。
实例方法:
- is_alive():返回进程是否在运行。
- join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的 timeout(可选参数)。
- start():进程准备就绪,等待 CPU 调度。
- run():strat() 调用 run 方法,如果实例进程时未制定传入 target,start 执行默认 run() 方法。
- terminate():不管任务是否完成,立即停止工作进程。
属性:
- authkey
- daemon:和线程的 setDeamon 功能一样(将父进程设置为守护进程,当父进程结束时,子进程也结束)。
- exitcode:(进程在运行时为 None、如果为 –N,表示被信号 N 结束)。
- name:进程名字。
- pid:进程号。
传递参数
# -*- coding: utf-8 -*-
import multiprocessing
# 多进程多进程传参
def run_process(n, a, name, age):
print(n, a, name, age)
if __name__ == '__main__':
# 可以利用换行是代码看起来更简洁
multiprocessing.Process(target=run_process,
args=(18, 1),
kwargs={'name': '张三', 'age': 18}).start()多进程不共享全局变量
因为属于不同的进程,进程与进程之间的变量不共享
import multiprocessing
import threading
def list_append(arr: list):
arr.append(1)
arr.append(2)
arr.append(3)
print('arr:', arr)
if __name__ == '__main__':
arr = []
# 普通方式添加
# list_append(arr)
# list_append(arr)
# 多线程方式添加
# threading.Thread(target=list_append, args=(arr, )).start()
# threading.Thread(target=list_append, args=(arr, )).start()
# 多进程方式添加
multiprocessing.Process(target=list_append, args=(arr,)).start() # 复制一份数据
multiprocessing.Process(target=list_append, args=(arr,)).start() # 复制一份数据
"""
多线程数据共享,会线程竞争问题,导致敏感数据出错,加锁可以保证敏感数据没有问题。
多进程数据不共享,会出现数据无法同步,会出现进程之间无法数据交换,使用进程之间的队列可以解决进程间数据交换问题。
"""多进程队列
Process 之间有时需要通信,操作系统提供了很多机制来实现进程间的通信。
可以使用 multiprocessing 模块的 Queue 实现多进程之间的数据传递,Queue 本身是一个消息列队程序,首先用一个小实例来演示一下 Queue 的工作原理:
# coding=utf-8
from multiprocessing import Queue
q = Queue(3) # 初始化一个 Queue 对象,最多可接收三条 put 消息
q.put("消息 1")
q.put("消息 2")
q.put("消息 3")
# 因为消息列队已满下面的 try 都会抛出异常,第一个 try 会等待 2 秒后再抛出异常,第二个 Try 会立刻抛出异常
try:
q.put("消息 4", True, 2)
except:
print("消息列队已满,现有消息数量:%s" % q.qsize())
try:
q.put_nowait("消息 4")
except:
print("消息列队已满,现有消息数量:%s" % q.qsize())
# 推荐的方式,先判断消息列队是否已满,再写入
if not q.full():
q.put_nowait("消息 4")
# 读取消息时,先判断消息列队是否为空,再读取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())运行结果:
消息列队已满,现有消息数量:3
消息列队已满,现有消息数量:3
消息1
消息2
消息3说明
初始化 Queue() 对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头);
Queue.qsize():返回当前队列包含的消息数量;Queue.empty():如果队列为空,返回 True,反之 False;Queue.full():如果队列满了,返回 True,反之 False;Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block 默认值为 True;- 如果
block使用默认值,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了 timeout,则会等待 timeout 秒,若还没读取到任何消息,则抛出 " Queue.Empty"异常; - 如果
block值为False,消息列队如果为空,则会立刻抛出Queue.Empty异常;
- 如果
Queue.get_nowait():相当Queue.get(False);Queue.put(item,[block[, timeout]]):将 item 消息写入队列,block 默认值为 True;- 如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了 timeout,则会等待 timeout 秒,若还没空间,则抛出
Queue.Full异常; - 如果 block 值为 False,消息列队如果没有空间可写入,则会立刻抛出
Queue.Full异常;
- 如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了 timeout,则会等待 timeout 秒,若还没空间,则抛出
Queue.put_nowait(item):相当Queue.put(item, False);
案例:多进程数据共享
import threading
import multiprocessing
def list_pop(pipe, name):
print(name, pipe.pop())
print(name, pipe.pop())
print(name, pipe.pop())
if __name__ == '__main__':
arr = [1, 2, 3, 4, 5, 6]
# 顺序执行
# list_pop(arr)
# list_pop(arr)
# 多线程
# threading.Thread(target=list_pop, args=(arr,)).start()
# threading.Thread(target=list_pop, args=(arr,)).start()
# 多进程
multiprocessing.Process(target=list_pop, args=(arr, 'p1')).start()
multiprocessing.Process(target=list_pop, args=(arr, 'p2')).start()
# print(arr)
"""
多进程数据不共享
缺点:一些数据被重复定义
优点:不会有竞争问题
多线程数据共享
缺点:敏感数据会出现竞争问题
优点:数据共享
多进程数据共享的方式
1. 使用进程之间的队列(进程之间可以共享的数据)
2. 可以任务记录到数据库之类的工具
"""{kind=link}