关系
在关系型数据库中,我们可以通过关系让不同表之间的字段建立联系。一般来说,定义关系需要两步,分别是创建外键和定义关系属性。 在复杂的多对多关系中,我们还需要定义关联表来管理关系。这一节我们 会学习如何使用 SQLAlchemy 在模型之间建立几种基础的关系模式。
一对多
我们将以作者和文章来演示一对多关系:一个作者可以写作多本小说。

在示例程序中,Author 类用来表示作者,Article 类用来表示文章
一对多关系示例
class Author(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String(70), unique=True)
phone = sa.Column(sa.String(20))
class Article(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
title = sa.Column(sa.String(50), index=True)
body = sa.Column(sa.Text)我们将在这两个模型之间建立一个简单的一对多关系,建立这个一对多关系的目的是在表示作者的 Author 类中添加一个关系属性 articles,作为集合(collection)属性,当我们对特定的 Author 对象调用 articles 属性会返 回所有相关的 Article 对象。 我们会在下面介绍如何一步步定义这个一对多关系。
添加数据
db.drop_all()
db.create_all()
author1 = Author(name='烽火戏诸侯', phone='110110')
author2 = Author(name='我吃西红柿', phone='110111')
author3 = Author(name='辰东', phone='110112')
db.session.add(author1)
db.session.add(author2)
db.session.add(author3)
db.session.commit()
article1 = Article(title='剑来',
body='大千世界,无奇不有。天道崩塌,我陈平安,唯有一剑,可搬山,断江,倒海,降妖,镇魔,敕神,摘星,摧城,开天!')
article2 = Article(title='雪中悍刀行',
body="该小说讲述一个关于庙堂权争与刀剑交错的时代,一个暗潮涌动粉墨登场的江湖。荣获首届网络文学双年奖之银奖作品。")
db.session.add(article1)
db.session.add(article2)
article3 = Article(title='星辰变',
body="当鱼跃龙门化身为龙的时候,他便不是鱼,而是龙!他是龙,龙则是不会呆在鱼群中,他需要的而是无限的天空,上穷碧落下黄泉,翱翔九天。")
article4 = Article(title='沧元图',
body="我叫孟川,今年十五岁,是东宁府“镜湖道院”的当代大师兄。")
article5 = Article(title='飞剑问道',
body="在这个世界,有狐仙、河神、水怪、大妖,也有求长生的修行者。")
db.session.add(article3)
db.session.add(article4)
db.session.add(article5)
article6 = Article(title='圣墟',
body="在破败中崛起,在寂灭中复苏。沧海成尘,雷电枯竭,那一缕幽雾又一次临近大地,世间的枷锁被打开了,一个全新的世界就此揭开神秘的一角……")
article7 = Article(title='遮天',
body="冰冷与黑暗并存的宇宙深处,九具庞大的龙尸拉着一口青铜古棺,亘古长存。")
article8 = Article(title='完美世界',
body="一粒尘可填海,一根草斩尽日月星辰,弹指间天翻地覆。群雄并起,万族林立,诸圣争霸,乱天动地。问苍茫大地,谁主沉浮?")
db.session.add(article6)
db.session.add(article7)
db.session.add(article8)
db.session.commit()定义外键
定义关系的第一步是创建外键。外键是(foreign key)用来在 A 表存储 B 表的主键值以便和 B 表建立联系的关系字段。 因为外键只能存储单一数据(标量),所以外键总是在“多”这一侧定义,多篇文章属于同一个作者, 所以我们需要为每篇文章添加外键存储作者的主键值以指向对应的作者。
在 Article 模型中,我们定义一个 author_id 字段作为外键:
class Article(db.Model):
# 1. 定义外键 在文章表中添加作者 id 的外键
author_id = sa.Column(sa.Integer, db.ForeignKey('author.id'))这个字段使用 db.ForeignKey 类定义为外键,传入关系另一侧的表名和主键字段名,即 author.id。实际的效果是将 article 表的 author_id 的值限制为 author 表的 id 列的值。它将用来存储 author 表中记录的主键值。
提示
外键字段的命名没有限制,因为要连接的目标字段是 author 表的 id 列,所以为了便于区分而将这个外键字段的名称命名为 author_id。
注意
传入 ForeignKey 类的参数 author.id ,其中 author 指的是 Author 模型对应的表名称,而 id 指的是字段名,即 表名.字段名。
模型类对应的表名由 Flask-SQLlchemy 生成,默认为类名称的⼩写形式,多个单词通过下划线分隔, 也可以显式地通过__tablename__ 属性自己指定,后面不再提示。
定义关系属性
定义关系的第二步是使用关系函数定义关系属性。关系属性在关系的出发侧定义,即一对多关系的 一 这一侧。 一个作者拥有多篇文章,在 Author 模型中,我们定义了一个 articles 属性来表示对应的多篇文章:
class Author(db.Model):
# 2. 定义关系 在作者表中太添加文章的引用
articles = db.relationship('Article')关系属性的名称没有限制,你可以自由修改。它相当于一个快捷查询,不会作为字段写入数据库中。 这个属性并没有使用 Column 类声明为列,而是使用了 db.relationship() 关系函数定义为关系属性, 因为这个关系属性返回多个记录,我们称之为集合关系属性。
relationship() 函数的第一个参数为关系另一侧的模型名称,它会告诉 SQLAlchemy 将 Author 类与 Article 类建立关系。 当这个关系属性被调用时,SQLAlchemy 会找到关系另一侧(即 article 表)的外键字段(即 author_id), 然后反向查询 article 表中所有 author_id 值 为当前表主键值(即 author.id)的记录, 返回包含这些记录的列表,也就 是返回某个作者对应的多篇文章记录。
建立关系
建立关系有两种方式,第一种方式是为外键字段赋值,比如:
>>> article1.author_id = 1
>>> db.session.commit()我们将 article1 对象的 author_id 字段的值设为 1,这会和 id 值为 1 的 Author 对象建立关系。 提交数据库改动后,如果我们对 id 为 1 的 author 对象调用 articles 关系属性,会看到 article1 对象包括在返回的 Article 对象列表中:
>>> author1.articles
[<Article 1>, <Article 2>]另一种方式是通过操作关系属性,将关系属性赋给实际的对象即可建立关系。 集合关系属性可以像列表一样操作,调用 append() 方法来与一个 Article 对象建立关系:
>>> author1.articles.append(article1)
>>> author1.articles.append(article2)
>>> db.session.commit()可以直接将关系属性赋值给一个包含 Article 对象的列表。
和前面的第一种方式类似,为了让改动生效,需要调用 db.session.commit() 方法提交数据库会话。 建立关系后,存储外键的 author_id 字段会自动获得正确的值,而调用 Author 实例的关系属性 articles 时,会获得所有建立关系的 Article 对象:
>>> article1.author_id
1
>>> author1.articles
[<Article 1>, <Article 2>]和主键类似,外键字段由 SQLAlchemy 管理,不需要手动设置。当通过关系属性建立关系后,外键字段会自动获得正确的值。
在后面的示例程序中,我们会统一使用第二种方式,即通过关系属性 来建立关系。
和 append() 相对,对关系属性调用 remove() 方法可以与对应的 Article 对象解除关系:
>>> author1.articles.remove(article2)
>>> db.session.commit()
>>> author1.articles
[<Article 1>]也可以使用 pop() 方法操作关系属性,它会与关系属性对应的列表的最后一个 Article 对象解除关系并返回该对象。
不要忘记在操作结束后需要调用 commit() 方法提交数据库会话,这样才可以把改动写入数据库。
在上面我们提到过,使用关系函数定义的属性不是数据库字段,而是类似于特定的查询函数。当某个 Article 对象被删除时,在对应 Author 对象 的 articles 属性调用时返回的列表也不会包含该对象。
在关系函数中,有很多参数可以用来设置调用关系属性进行查询时的具体行为。
常用的 SQLAlchemy 关系函数参数
| 参数名 | 说 明 |
|---|---|
| back_populates | 定义反向引用,用于建立双向关系,在关系的另一侧也必须显式定义关系属性 |
| backref | 添加反向引用, A 动在另一侧建立关系属性,是 back_populates 的简化版 |
| lazy | 指定如何加载相关记录,具体选项见下表 |
| uselist | 指定是否使用列表的形式加载记录,设为 False 则使用标量 (scalar) |
| cascade | 设置级联操作 |
| order_by | 指定加载相关记录时的排序方式 |
| secondary | 在多对多关系中指定关联表 |
| primaryjoin | 指定多对多关系中的一级联结条件 |
| secondaryjoin | 指定多对多关系中的二级联结条件 |
当关系属性被调用时,关系函数会加载相应的记录,下表列出了控制 关系记录加载方式的 lazy 参数的常用选项。
常用的 SQLAlchemy 关系记录加载方式(lazy 参数可选值)
| 关系加载方式 | 说 明 |
|---|---|
| select | 在必要时一次性加载记录,返回包含记录的列表(默认值),等同于 lazy=Ture |
| joined | 和父査询一样加载记录,但使用联结,等同于 lazy=False |
| immediate | 一旦父查询加载就加载 |
| subquery | 类似于 joined ,不过将使用子查询 |
| dynamic | 不直接加载记录,而是返回一个包含相关记录的 query 对象,以便再继续附加查询函数对结果进行过滤 |
dynamic 选项仅用于集合关系属性,不可用于多对一、一对一或是在关系函数中将 uselist 参数设为 False 的情况。
许多教程和示例使用 dynamic 来动态加载所有集合关系属性对应的记录,这是应该避免的行为。 使用 dynamic 加载方式意味着每次操作关系都会执行一次 SQL 查询,这会造成潜在的性能问题。 大多数情况下我们只需要使用默认值(select),只有在调用关系属性会返回大量记录, 并且总是需要对关系属性返回的结果附加额外的查询时才需要使用动态加载(lazy='dynamic')。
建立双向关系
我们在 Author 类中定义了集合关系属性 articles,用来获取某个作者拥有的多篇文章记录。 在某些情况下,你也许希望能在 Article 类中定义一个类似的 author 关系属性,当被调用时返回对应的作者记录, 这类返回单个值的关系属性被称为标量关系属性。 而这种两侧都添加关系属性获取对方记录的关系我们称之为双向关系(bidirectional relationship)。
双向关系并不是必须的,但在某些情况下会非常方便。双向关系的建立很简单, 通过在关系的另一侧也创建一个 relationship() 函数,我们就可以在两个表之间建立双向关系。 我们使用作者(Author)和文章(Article)的一对多关系来进行演示,建立双向关系后的 Author 和 Article 类
基于一对多关系的双向关
class Author(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String(70), unique=True)
phone = sa.Column(sa.String(20))
# 2. 定义关系
articles = db.relationship('Article')
class Article(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
title = sa.Column(sa.String(50), index=True)
body = sa.Column(sa.Text)
# 1. 定义外键
author_id = sa.Column(sa.Integer, db.ForeignKey('author.id'))
# 3. back_populates='articles' 添加反向关系
# 可以通过 Article.author 方式反向取到 Author 对象
author = db.relationship('Author', back_populates='articles')在 多 这一侧的 Article(书)类中,我们新创建了一个 author 关系属性,这是一个标量关系属性,调用它会获取对应的 Author(作者)记录; 而在 Author(作者)类中的 articles 属性则用来获取对应的多个 Article(文章)记录。 在关系函数中,我们使用 back_populates 参数来连接对方,back_populates 参数的值需要设为关系另一侧的关系属性名。
因为之前已经有数据了,而新增的反向关系没有新建字段,所以直接可以使用。
设置双向关系后,除了通过集合属性 articles 来操作关系,我们也可以使 用标量属性 author 来进行关系操作。 比如,将一个 Author 对象赋值给某个 Article 对象的 author 属性,就会和这个 Article 对象建立关系:
article1 = Article.query.get(1)
print(article1.author)
author1 = Author.query.get(3)
print(author1.articles)
article1.author = author1
print(article1.author)相对的,将某个 Article 的 author 属性设为 None,就会解除与对应 Author 对象的关系:
article1.author = None
print(article1.author)需要注意的是,只需要在关系的一侧操作关系。当为 Article 对象的 author 属性赋值后,对应 Author 对象的 articles 属性的返回值也会自动包含这个 Article 对象。
反之,当某个 Author 对象被删除时,对应的 Article 对象的 author 属性被调用时的返回值也会被置为空(即 NULL,会返回 None)。
其他关系模式建立双向关系的方式完全相同,在下面介绍不同的关系模式时我们会简单说明。
backref 简化关系定义
在介绍关系函数的参数时,我们曾提到过,使用关系函数中的 backref 参数可以简化双向关系的定义。 以一对多关系为例,backref 参数用来自动为关系另一侧添加关系属性,作为反向引用(back reference),赋予的值会作为关系另一侧的关系属性名称。 比如,我们在 Author 一侧的关系函数中将 backref 参数设为 author,SQLAlchemy 会自动为 Article 类添加一个 author 属性。
class Author(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String(70), unique=True)
phone = sa.Column(sa.String(20))
# # 2. 定义关系
# articles = db.relationship('Article')
# 4. 可以直接添加反向引用
articles = db.relationship('Article', backref='author')
# 4 等价于 2 + 3
class Article(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
title = sa.Column(sa.String(50), index=True)
body = sa.Column(sa.Text)
# 1. 定义外键
author_id = sa.Column(sa.Integer, db.ForeignKey('author.id'))
# # 3. back_populates='articles' 添加反向关系
# # 可以通过 Article.author 方式反向取到 Author 对象
# author = db.relationship('Author', back_populates='articles')在定义集合属性 articles 的关系函数中,我们将 backref 参数设为 author,这会同时在 Article 类中添加了一个 author 标量属性。这时我们仅需要定义一个 关系函数,虽然 author 是一个 看不见的关系属性,但在使用上和定义两个关系函数并使用 back_populates 参数的效果完全相同。
尽管使用 backref 非常方便,但通常来说 显式好过隐式,所以我们应该尽量使用 back_populates 定义双向关系。
多对多
我们将使用学生和老师来演示多对多关系:每个学生有多个老师,而 每个老师有多个学生。
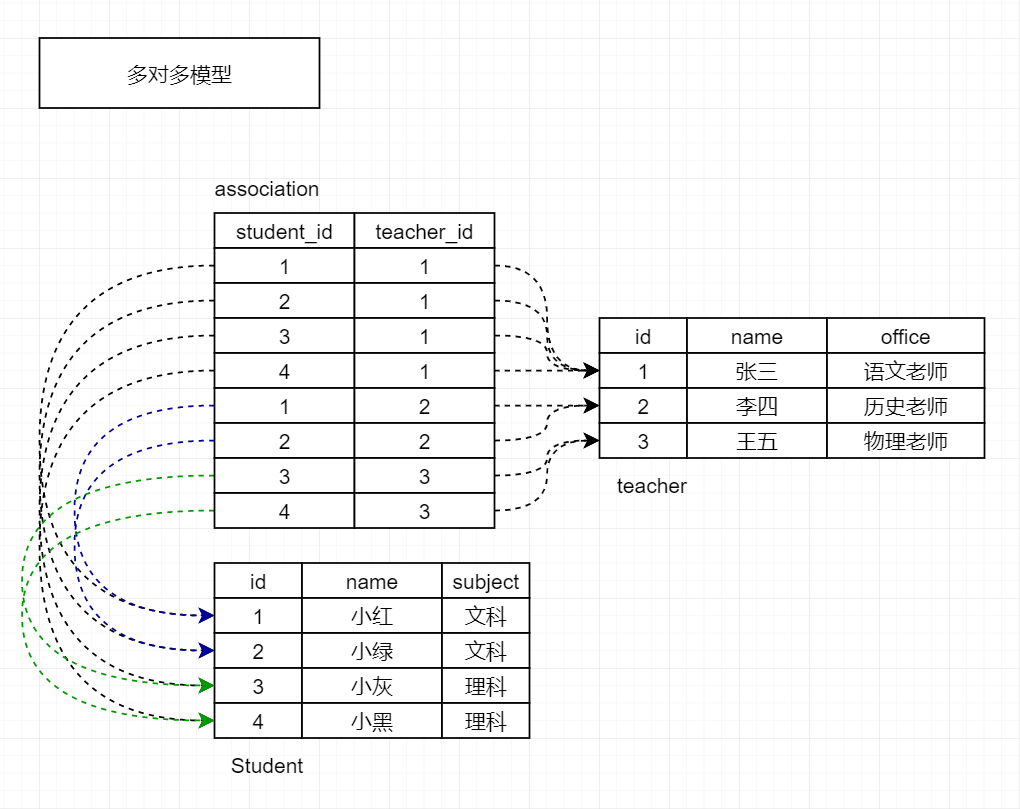
在示例程序中, Student 类表示学生, Teacher 类表示老师。在这两个模型之间建立多对多关系后, 我们需要在 Student 类中添加一个集合关系属性 teachers,调用它可以获取某个学生的多个老师,而不同的学生可以和同一个老师建立关系。
在一对多关系中,我们可以在 多 这一侧添加外键指向 一 这一侧,外键只能存储一个记录,但是在多对多关系中, 每一个记录都可以与关系另一侧的多个记录建立关系,关系两侧的模型都需要存储一组外键。
在 SQLAlchemy 中,要想表示多对多关系,除了关系两侧的模型外,我们还需要创建一个关联表(association table)。 关联表不存储数据,只用来存储关系两侧模型的外键对应关系,如代码所示。
建立多对多关系
association_table = db.Table(
'association',
sa.Column('student_id', sa.Integer, db.ForeignKey('student.id')),
sa.Column('teacher_id', sa.Integer, db.ForeignKey('teacher.id'))
)
class Student(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String(70), unique=True)
subject = sa.Column(sa.String(20))
teachers = db.relationship('Teacher',
secondary=association_table,
back_populates='students')
class Teacher(db.Model):
id = sa.Column(sa.Integer, primary_key=True)
name = sa.Column(sa.String(70), unique=True)
office = sa.Column(sa.String(20))
students = db.relationship('Student',
secondary=association_table,
back_populates='teachers')关联表使用 db.Table 类定义,传入的第一个参数是关联表的名称。我们在关联表中定义了两个外键字段:teacher_id 字段存储 Teacher 类的主键,student_id 存储 Student 类的主键。借助关联表这个中间人存储的外键对,可以把多对多关系分化成两个一对多关系。
当我们需要查询某个学生记录的多个老师时,我们先通过学生和关联表的一对多关系查找所有包含该学生的关联表记录, 然后就可以从这些记录中再进一步获取每个关联表记录包含的老师记录。 假设学生记录的 id 为 1,那么通过查找关联表中 student_id 字段为 1 的记录, 就可以获取到对应的 teacher_id 值(分别为 3 和 4),通过外键值就可以在 teacher 表里获取 id 为 3 和 4 的记录, 最终,我们就获取到 id 为 1 的学生记录相关联的所有老师记录。
在 Student 类中定义一个 teachers 关系属性用来获取老师集合。在多对多关系中定义关系函数,除了第一个参数是关系另一侧的模型名称外, 我们还需要添加一个 secondary 参数,把这个值设为关联表的名称。
为了便于实现真正的多对多关系,我们需要建立双向关系。建立双向关系后,多对多关系会变得更加直观。 在 Student 类上的 teachers 集合属性会 返回所有关联的老师记录,而在 Teacher 类上的 students 集合属性会返回所有相关的学生记录:
class Student(db.Model):
# 添加老师关系引用
teachers = db.relationship('Teacher',
secondary=association_table,
back_populates='students')
class Teacher(db.Model):
# 添加学生关系引用
students = db.relationship('Student',
secondary=association_table,
back_populates='teachers')除了在声明关系时有所不同,多对多关系模式在操作关系时和其他关系模式基本相同。调用关系属性 student.teachers 时,SQLAlchemy 会直接返回关系另一侧的 Teacher 对象,而不是关联表记录,反之亦同。和其他关系模式中的集合关系属性一样, 我们可以将关系属性 teachers 和 students 像列 表一样操作。
比如,当你需要为某一个学生添加老师时,对关系属性使用 append() 方法即可。如果你想要解除关系,那么可以使用 remove() 方法。
关联表由 SQLAlchemy 接管,它会帮我们管理这个表:我们只需要像往常一样通过操作关系属性来建立或解除关系, SQLAlchemy 会自动在关联表中创建或删除对应的关联表记录,而不用手动操作关联表。
同样的,在多对多关系中我们也只需要在关系的一侧操作关系。当为学生 A 的 teachers 添加了老师 B 后, 调用老师 B 的 students 属性时返回的学生记录也会包含学生 A,反之亦同。
@app.cli.command()
def create():
"""新增数据"""
db.drop_all()
db.create_all()
stu1 = Student(name='小红', subject='文科')
stu2 = Student(name='小绿', subject='文科')
stu3 = Student(name='小灰', subject='理科')
stu4 = Student(name='小黑', subject='理科')
db.session.add(stu1)
db.session.add(stu2)
db.session.add(stu3)
db.session.add(stu4)
db.session.commit()
tea1 = Teacher(name='张三', office='语文老师')
tea2 = Teacher(name='李四', office='历史老师')
tea3 = Teacher(name='王五', office='物理老师')
db.session.add(tea1)
db.session.add(tea2)
db.session.flush()
tea1.students.append(stu1)
tea1.students.append(stu2)
tea1.students.append(stu3)
tea1.students.append(stu4)
tea2.students.append(stu1)
tea2.students.append(stu2)
tea3.students.append(stu3)
tea3.students.append(stu4)
db.session.commit()
@app.cli.command()
def rel():
tea = Teacher.query.get(2)
print(tea.students)
# 删除对应关系
stu = Student.query.get(1)
# stu = tea.students[0]
tea.students.remove(stu)
print(tea.students)
db.session.commit()