gunicorn
在开发时,我们使用 flask run 命令启动的开发服务器是由 Werkzeug 提供的。细分的话,Werkzeug 提供的这个开发服务器应该被称为 WSGI 服务器,而不是单纯意义上的 Web 服务器。在生产环境中,我们需要一个更强健、性能更高的 WSGI 服务器。这些 WSGI 服务器也被称为独立 WSGI 容器(Standalone WSGI Container),因为它们可以承载我们编写的 WSGI 程序,然后处理 HTTP 请求和响应。
通常我们会根据程序的特点来选,主流的选择是使用 Gunicorn 和 uWSGI。在这里我们将使用 Gunicorn(意为 Green Unicorn),它使用起来相对简单,容易配置,而且性能优秀。
gunicorn 的简介
Gunicorn 是基于 unix 系统,被广泛应用的高性能的 Python WSGI HTTP Server。用来解析 HTTP 请求的网关服务。
它通常是在进行反向代理(如 nginx),或者进行负载均衡(如 AWS ELB)和一个 web 应用(比如 Django 或者 Flask)之间。
它的运行模型基于 pre-fork worker 模型,即就是支持 eventlet,也支持 greenlet。
其特点:
1、能和大多数的 Python Web 框架兼容; 2、简单易上手; 3、轻量级的资源消耗; 4、目前,gunicorn 只能运行在 Linux 环境中,不支持 windows 平台。
谈谈 WSGI HTTP Server
所谓 WSGI(Web Server Gateway Interface)。它不是 web server,也不是 web app;而正是为了将 web 和 app 解耦、再连接起来的一道桥梁。因为它是一种通用的接口规范,规定了 web server(如 Apache、Nginx)和 web app(或 web app 框架)之间的标准。
因为如此,web app 开发者就能专注于业务逻辑、专注于 HTML 文档的生成,而不用操心繁琐的网络底层实现(HTTP 请求接收、建立连接、返回响应等),并能方便地组合搭配不同的 web server + web app 框架了。
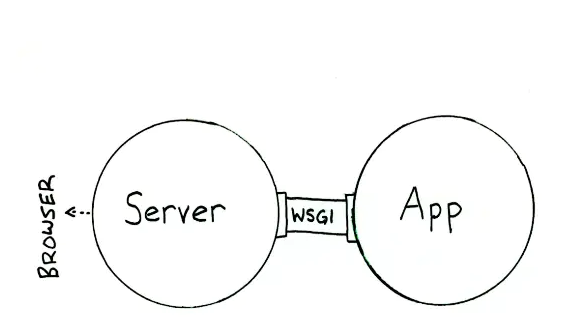
谈谈 pre-fork worker model
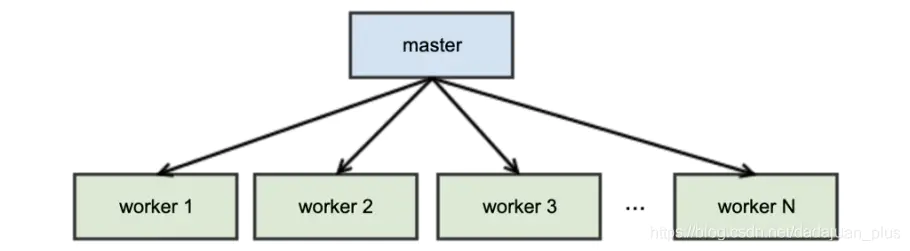
对于 Gunicorn 来说,gunicorn 是 WSGI 的实现,但同时也自带 web server,能直接对外提供 web 服务。包括大部分的 web app 框架,比如 Flask 和 Django 也都带有 web server。 但是,在生产环境中,一般它们都是各司其职,Web 框架 Flask、Django 只用于写 app、Gunicorn 只用于运行和管理 Python web app,而在它们之前看有专门的 web server,比如 Nginx。
gunicorn 的使用
gunicorn 支持使用不同的 worker 进程类型,可通过 worker-class 参数配置。 启动后,gunicorn 的所有 worker 共用一组 listener(Gunicorn 支持绑定多个 socket,所以说是一组)。在启动 worker 时,worker 内为每个 listener 创建一个 WSGI server,接收 HTTP 请求,并调用 app 对象去处理请求。
gunicorn 的工作模式一般分为同步 worker 使用和异步 worker 使用。
workers 模式
1、同步 worker(Sync Worker)
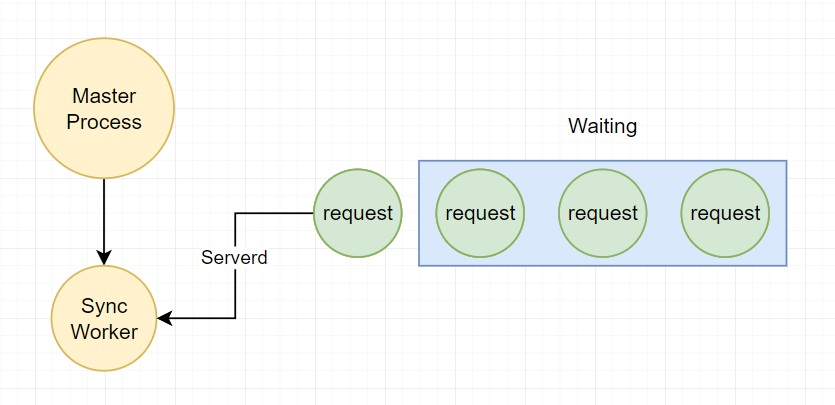
默认的、最简单的 worker 模式,就是同步模式。 每个 worker 进程,一次只处理一个请求;如果此时又有其他请求被分配到了这个 worker 进程中,那只能被堵塞了,只能等待第一个请求完成。 并且,一个请求一个进程,并发时,是非常消耗 CPU 和内存的。
注:因此,只能适合在访问量不大、CPU 密集而非 I/O 的情形。 但是也有好处,好处就是,即使一个 worker 的进程 crash 了,也只会影响到一个请求。不会影响其他的请求
2、异步 workers(Async Worker)
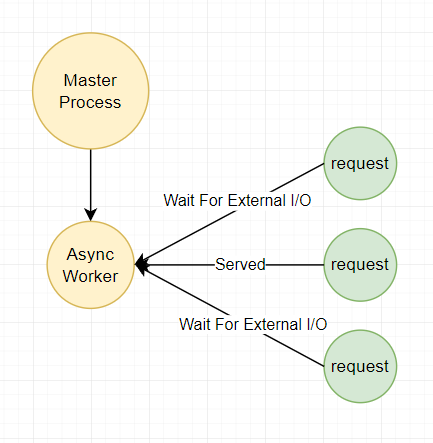
异步 worker 有 Gevent 和 Eventlet 两种,都是基于 Greenlet 实现的。 当使用了异步 worker,就能同时处理不止一个请求,就不会出现上面同步 worker 那样,当一个请求就把后续请求都 block 堵塞住了。
注:gunicorn 允许通过设置对应的 worker 类来使用这些异步 Python 库。
例如:我们想在单核机器上运行的 gevent:
gunicorn --worker-class=gevent --worker-connections=1000 --workers=3 main:app解释:worker-connection 是对于 gevent worker 类的特殊设置。(2CPU)+1 仍然是建议的 worker 数量。 因为这里是单核,我们设置的是 3 个 worker。在这种情况下,最大的并发请求数是 3000(3 个 worker * 1000 个连接数/worker)
多线程模式
Gunicorn 还允许每个 worker 拥有多个线程。在这种场景下,Python 应用程序每个 worker 都会加载一次,同一个 worker 生成的每个线程共享相同的内存空间。
为了在 Gunicorn 中使用多线程。我们使用了 threads 模式。每一次我们使用 threads 模式,worker 的类就会是 gthread:
gunicorn --workers=5 --threads=2 main:app上一条命令等同于:
gunicorn --workers=5 --threads=2 --worker-class=gthread main:app在我们的例子里面最大的并发请求数就是 worker * 线程,也就是 10。 在使用 worker 和多线程模式时建议的最大并发数量仍然是 (2*CPU)+1 。 因此如果我们使用四核(4 个 CPU)机器并且我们想使用 workers 和多线程模式,我们可以使用 3 个 worker 和 3 个线程来得到最大为 9 的并发请求数量。
gunicorn --workers=3 --threads=3 main:app伪线程模式
有一些 Python 库比如(gevent 和 Asyncio)可以在 Python 中启用多并发。那是基于协程实现的“伪线程”。
Gunicrn 允许通过设置对应的 worker 类来使用这些异步 Python 库。
这里的设置适用于我们想要在单核机器上运行的gevent:
gunicorn --worker-class=gevent --worker-connections=1000 --workers=3 main:appworker-connections 是对于 gevent worker 类的特殊设置。
(2*CPU)+1 仍然是建议的workers 数量。因为我们仅有一核,我们将会使用 3 个 worker。
在这种情况下,最大的并发请求数量是 3000。(3 个 worker * 1000 个连接/worker)
gunicorn 是如何实现高并发的?
对于 gunicorn 而言,当启动时,就已经把 worker 进程预先 fork 出来了。当多个请求到来的时候,会轮流复用这些 worker 进程,从而能提高服务器的并发负载能力。
对于 worker 数的配置,一般推荐 2CPU 数 +1。这样一来,在任何时间,都有大概一般的 worker 是在做 I/O,剩下一般才是需要 CPU 的。
如果在开多进程的同时,也开多线程(也就是选择 gthread 类型的 worker),那么,配置总的并发数(worker 进程数线程数),仍然建议 2CPU 数 +1
并发 vs. 并行
- 并发是指同时执行 2 个或更多任务,这可能意味着其中只有一个正在处理,而其他的处于暂停状态。
- 并行是指两个或多个任务正在同时执行。
在 Python 中,线程和伪线程都是并发的一种方式,但并不是并行的。但是 workers 是一系列基于并发或者并行的方式。
理论讲的很不错,但我应该怎样在程序中使用呢?
通过调整 Gunicorn 设置,我们希望优化应用程序性能。
- 如果这个应用是 I/O 受限,通常可以通过使用“伪线程”(gevent 或 asyncio)来得到最佳性能。正如我们了解到的,Gunicorn 通过设置合适的 worker 类 并将
workers数量调整到(2*CPU)+1来支持这种编程范式。 - 如果这个应用是 CPU 受限,那么应用程序处理多少并发请求就并不重要。唯一重要的是并行请求的数量。因为 Python’s GIL,线程和“伪线程”并不能以并行模式执行。实现并行性的唯一方法是增加
workers的数量到建议的(2*CPU)+1,理解到最大的并行请求数量其实就是核心数。 - 如果不确定应用程序的内存占用,使用
多线程以及相应的 gthread worker 类 会产生更好的性能,因为应用程序会在每个 worker 上都加载一次,并且在同一个 worker 上运行的每个线程都会共享一些内存,但这需要一些额外的 CPU 消耗。 - 如果你不知道你自己应该选择什么就从最简单的配置开始,就只是
workers数量设置为(2*CPU)+1并且不用考虑多线程。从这个点开始,就是所有测试和错误的基准环境。如果瓶颈在内存上,就开始引入多线程。如果瓶颈在 I/O 上,就考虑使用不同的 Python 编程范式。如果瓶颈在 CPU 上,就考虑添加更多内核并且调整workers数量。
使用详解
使用 gunicorn 监听请求,运行以下命令
gunicorn -w 2 -b 0.0.0.0:8000 wsgi:app- -w: 指定 fork 的 worker 进程数
- -b: 指定绑定的端口
- test: 模块名,python 文件名
- application: 变量名,python 文件中可调用的 wsgi 接口名称(app 对象)
gunicorn 相关参数
指定一个配置文件(py 文件)
-c CONFIG,--config=CONFIG与指定 socket 进行绑定
-b BIND,--bind=BIND后台进程方式运行 gunicorn 进程
-D,--daemon工作进程的数量
-w WORKERS,--workers=WORKERS工作进程类型,包括 sync(默认),eventlet,gevent,tornado,gthread,gaiohttp
-k WORKERCLASS,--worker-class=WORKERCLASS最大挂起的连接数
--backlog INT日志输出等级
--log-level LEVEL访问日志输出文件
--access-logfile FILE错误日志输出文件
--error-logfile FILEgunicorn 参数配置文件
-c CONFIG,--config=CONFIG 指定一个配置文件(py 文件) gunicorn 可以写在配置文件中,下面举列说明配置文件的写法,gunicorn.conf.py
bind = "0.0.0.0:8000"
workers = 2运行以下命令:
gunicorn -c gunicorn.conf.py wsgi:app运行结果和使用命令行参数,结果一样。
gunicorn 配置文件是一个 python 文件,因此可以实现更复杂的逻辑,如下:
# filename: gunicorn.conf.py
import os
import multiprocessing
bind = '127.0.0.1:5000' # 绑定 ip 和端口号
backlog = 512 # 监听队列
chdir = os.path.dirname(os.path.abspath(__file__)) # gunicorn 要切换到的目的工作目录
timeout = 30 # 超时
worker_class = 'sync' # 使用 gevent 模式,还可以使用 sync 模式,默认的是 sync 模式
workers = multiprocessing.cpu_count() * 2 + 1 # 进程数
threads = 2 # 指定每个进程开启的线程数
loglevel = 'info' # 日志级别,这个日志级别指的是错误日志的级别,而访问日志的级别无法设置
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' # 设置 gunicorn 访问日志格式,错误日志无法设置
"""
其每个选项的含义如下:
h remote address
l '-'
u currently '-', may be user name in future releases
t date of the request
r status line (e.g. ``GET / HTTP/1.1``)
s status
b response length or '-'
f referer
a user agent
T request time in seconds
D request time in microseconds
L request time in decimal seconds
p process ID
"""
accesslog = os.path.join(chdir, "log/gunicorn_access.log") # 访问日志文件
errorlog = os.path.join(chdir, "log/gunicorn_error.log") # 访问日志文件使用配置文件启动 Gunicorn
gunicorn --config=gunicorn.conf.py wsgi:app和上面用命令行配置的效果完全一样,当然两者还可以结合起来用:
gunicorn --config=gunicorn.conf.py --worker-class=eventlet wsgi:appworker-class 默认是 sync (同步),我们也可以配置成了 eventlet(并发的)
gunicorn 相关参数说明
1)-c CONFIG,–config=CONFIG
指定一个配置文件(py文件)
2)-b BIND,–bind=BIND
与指定socket进行绑定
3)-D,–daemon
后台进程方式运行gunicorn进程
4)-w WORKERS,–workers=WORKERS
工作进程的数量
5)-k WORKERCLASS,–worker-class=WORKERCLASS
工作进程类型,包括sync(默认),eventlet,gevent,tornado,gthread,gaiohttp
6)–backlog INT
最大挂起的连接数
7)–log-level LEVEL
日志输出等级
8)–access-logfile FILE
访问日志输出文件
9)–error-logfile FILE
错误日志输出文件部署
1、首先需要安装 gunicorn 应用
1.1、首先我们需要先创建虚拟环境
cd /opt/typhoonae
mkdir venv
python3 -m venv venv1.2、然后激活虚拟环境
source venv/bin/activate1.3、然后根据 requirements.txt 文件安装依赖包
pip3 install -r requirements.txt1.4、安装 gunicorn,安装直接可以使用 pip
pip3 install gunicorn1.5、在项目根目录下创建一个 app.py 文件
from app import create_app
application = create_app('production')
if __name__ == '__main__':
application.run()此时,不再通过 app.py 启动服务,那只在开发的时候使用
然后启动服务:
gunicorn -w 4 -b 127.0.0.1:8000 'app:application'使用案例
一般情况下,在生产环境中,进程的启停和状态的监控最好应用 supervisor 之类的监控工具。然后在 gunicorn 的前端防止一个 http proxy server,比如 nginx。
# filename: gunicorn_demo.py
import multiprocessing
bind = '127.0.0.1:8000'
workers = multiprocessing.cpu_count() * 2 + 1
backlog = 2048
worker_class = "gevent"
worker_connections = 1000
daemon = False
debug = True
proc_name = 'gunicorn_demo'
pidfile = './log/gunicorn.pid'
errorlog = './log/gunicorn.log'注:gunicorn 的配置文件必须为一个 python 文件,只是将命令行中的参数写进 py 文件中而已,如果需要设置哪个参数,则在 py 文件中为该参数赋值即可。
例如:
配置文件为 example.py
# example.py
bind = "127.0.0.1:8000"
workers = 2运行 gunicorn 命令为:
gunicorn -c example.py test:app
# 等同于:
gunicorn -w 2 -b 127.0.0.1:8000 test:app此时,当然了,配置文件还可以设置的更加复杂,根据实际情况而言:
假如:
配置文件为:gunicorn_test.py
# gunicorn_test.py
import logging
import logging.handlers
from logging.handlers import WatchedFileHandler
import os
import multiprocessing
bind = '127.0.0.1:8000' # 绑定 ip 和端口号
backlog = 512 # 监听队列
chdir = '/home/test/server/bin' # gunicorn 要切换到的目的工作目录
timeout = 30 # 超时
worker_class = 'gevent' # 使用 gevent 模式,还可以使用 sync 模式,默认的是 sync 模式
workers = multiprocessing.cpu_count() * 2 + 1 # 进程数
threads = 2 # 指定每个进程开启的线程数
loglevel = 'info' # 日志级别,这个日志级别指的是错误日志的级别,而访问日志的级别无法设置
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' # 设置 gunicorn 访问日志格式,错误日志无法设置
"""
其每个选项的含义如下:
h remote address
l '-'
u currently '-', may be user name in future releases
t date of the request
r status line (e.g. ``GET / HTTP/1.1``)
s status
b response length or '-'
f referer
a user agent
T request time in seconds
D request time in microseconds
L request time in decimal seconds
p process ID
"""
accesslog = "/home/test/server/log/gunicorn_access.log" # 访问日志文件
errorlog = "/home/test/server/log/gunicorn_error.log" # 错误日志文件那么此时执行命令就为:
gunicorn -c gunicorn_test.py test:app