数组的操作
可以通过一些函数,非常方便的操作数组的形状。
修改数组维度
ndarray.reshape(shape, order)- 返回一个具有相同数据域,但 shape 不一样的视图
- 行、列不进行互换
reshape 和 resize 方法:
两个方法都是用来修改数组形状的,但是有一些不同。
reshape是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的。调用方式:python# reshape 不会影响原数组本身 a1 = np.random.randint(0, 10, size=(3, 4)) print('a1:\n', a1) a2 = a1.reshape((2, 6)) print('a2:\n', a2) """ a1: [[1 3 3 3] [7 8 4 0] [8 5 5 3]] a2: [[1 3 3 3 7 8] [4 0 8 5 5 3]] """python# 一维 ---> 三维 a3 = a2.reshape((2, 3, 2)) print('a3:\n', a3) """ a3: [[[1 3] [3 3] [7 8]] [[4 0] [8 5] [5 3]]] """resize是将数组转换成指定的形状,会直接修改数组本身。并不会返回任何值。调用方式:python# resize 不会影响原数组本身 a4 = np.random.randint(0, 10, size=(3, 4)) print('a4:\n', a4) a5 = a4.resize((2, 6)) # a1 本身发生了改变 print('a5:\n', a5) print('a4:\n', a4) """ a4: [[7 2 9 5] [5 8 0 1] [1 3 1 6]] a5: None a4: [[7 2 9 5 5 8] [0 1 1 3 1 6]] """
flatten 和 ravel 方法:
两个方法都是将多维数组转换为一维数组,但是有以下不同:
flatten是将数组转换为一维数组后,然后将这个拷贝返回回去,所以后续对这个返回值进行修改不会影响之前的数组。ravel是将数组转换为一维数组后,将这个视图(可以理解为引用)返回回去,所以后续对这个返回值进行修改会影响之前的数组。 比如以下代码:
x = np.array([[1, 2], [3, 4]])
# flatten 返回一份新的
x_flatten = x.flatten()
# 浅拷贝,可以修改原来的
x_ravel = x.ravel()
x.flatten()[1] = 100 # 此时的 x[0] 的位置元素还是 1
x.ravel()[1] = 100 # 此时 x[0] 的位置元素是 100ndarray.T
- 数组的转置
- 将数组的行、列进行互换
数组操作
索引、切片
一维、二维、三维的数组如何索引?
- 直接进行索引,切片
- 对象[:, :] -- 先行后列
a1 = np.arange(0, 10)
print('a1:\n', a1)
"""
a1:
[0 1 2 3 4 5 6 7 8 9]
"""二维数组索引方式:
# 二维数组切片
a2 = np.arange(0, 10).reshape(2, 5)
print('a2:\n', a2)
"""
a2:
[[0 1 2 3 4]
[5 6 7 8 9]]
"""
# 对象 [:, :] -- 先行后列
print('a2[:, 2:]:\n', a2[:, 2:])
"""
a2[:, 2:]:
[[2 3 4]
[7 8 9]]
"""三维数组索引方式:
import numpy as np
# 三维
a1 = np.array([[[1, 2, 3], [4, 5, 6]], [[12, 3, 34], [5, 6, 7]]])
print(a1)
# 返回结果
"""
array([[[1, 2, 3],
[4, 5, 6]],
[[12, 3, 34],
[5, 6, 7]]])
"""
# 索引、切片
print(a1[0, 0, 1]) # 输出:2举例:
- 获取第一个股票的前 3 个交易日的收盘价格
- 获取日期,最高价,最低价,收盘价
提示
文件下载 stock_day.csv
import numpy as np
arr_stock = np.loadtxt("stock_day.csv", dtype=str, delimiter=',', skiprows=1)
# print(arr_stock)
# 获取第一个股票的前 3 个交易日的收盘价格
print(arr_stock[:3, :])
# 日期,最高价,收盘价,最低价
print(arr_stock[:3, :4])数组的切割 (了解)
通过hsplit和vsplit以及array_split可以将一个数组进行切割。
hsplit:按照水平方向进行切割。用于指定分割成几列,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:pythonimport numpy as np a1 = np.arange(16).reshape(4, 4) """水平切割""" print('a1:\n', a1) # horizontally 水平 h_sub_a1, h_sub_a2 = np.hsplit(a1, 2) # 分割成两部分 print('sub_a1:\n', h_sub_a1) print('sub_a2:\n', h_sub_a2) """ a1: [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] h_sub_a1: [[ 0 1] [ 4 5] [ 8 9] [12 13]] h_sub_a2: [[ 2 3] [ 6 7] [10 11] [14 15]] """ # 代表在下标为 1 的地方切一刀,下标为 2 的地方切一刀,分成三部分 h_sub_a1, h_sub_a2, h_sub_a3 = np.hsplit(a1, [1, 2]) print('sub_a1:\n', h_sub_a1) print('sub_a2:\n', h_sub_a2) print('sub_a3:\n', h_sub_a3) """ h_sub_a1: [[ 0] [ 4] [ 8] [12]] h_sub_a2: [[ 1] [ 5] [ 9] [13]] h_sub_a3: [[ 2 3] [ 6 7] [10 11] [14 15]] """vsplit:按照垂直方向进行切割。用于指定分割成几行,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:python# vertically 垂直 v_sub_a1, v_sub_a2 = np.vsplit(a1, 2) # 代表按照行总共分成 2 个数组 print('v_sub_a1:\n', v_sub_a1) print('v_sub_a2:\n', v_sub_a2) """ a1: [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] v_sub_a1: [[0 1 2 3] [4 5 6 7]] v_sub_a2: [[ 8 9 10 11] [12 13 14 15]] """ # 代表在下标为 1 的地方切一刀,下标为 2 的地方切一刀,分成三部分 v_sub_a1, v_sub_a2, v_sub_a3 = np.hsplit(a1, [1, 2]) print('v_sub_a1:\n', v_sub_a1) print('v_sub_a2:\n', v_sub_a2) print('v_sub_a3:\n', v_sub_a3) """ v_sub_a1: [[ 0] [ 4] [ 8] [12]] v_sub_a2: [[ 1] [ 5] [ 9] [13]] v_sub_a3: [[ 2 3] [ 6 7] [10 11] [14 15]] """split/array_split(array,indicate_or_seciont,axis):用于指定切割方式,在切割的时候需要指定是按照行还是按照列,axis=1代表按照列,axis=0代表按照行。示例代码如下:pythonnp.array_split(x,2,axis=0) # 按照垂直方向切割成 2 部分 >>> [array([[0., 1., 2., 3.], [4., 5., 6., 7.]]), array([[ 8., 9., 10., 11.], [12., 13., 14., 15.]])]
数据的拼接
如果有多个数组想要组合在一起,也可以通过其中的一些函数来实现。
vstack:将数组按垂直方向进行叠加。数组的列数必须相同才能叠加。示例代码如下:pythonimport numpy as np a1 = np.arange(0, 10).reshape(2, 5) a2 = np.arange(10, 20).reshape(2, 5) print('a1:\n', a1) print('a2:\n', a2) v_a3 = np.vstack([a1, a2]) print('v_a3:\n', v_a3) """ a1: [[0 1 2 3 4] [5 6 7 8 9]] a2: [[10 11 12 13 14] [15 16 17 18 19]] v_a3: [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14] [15 16 17 18 19]] """hstack:将数组按水平方向进行叠加。数组的行必须相同才能叠加。示例代码如下:pythonh_a3 = np.hstack([a1, a2]) print('h_a3:\n', h_a3) """ h_a3: [[ 0 1 2 3 4 10 11 12 13 14] [ 5 6 7 8 9 15 16 17 18 19]] """
数组广播(重点)
数组运算
arr = np.array([1, 2, 3])
arr + 1
arr / 2# 可以对比 python 列表的运算,看出区别
a = [1, 2, 3]
a * 3数组在进行矢量化运算时,要求数组的形状是相等的 。当形状不相等的数组执行算术运算的时候,就会出现广播机制,该机制会对数组进行扩展,使数组的 shape 属性值一样,这样,就可以进行矢量化运算了。下面通过一个例子进行说明:
arr1 = np.array([[0], [1], [2], [3]])
arr1.shape
# (4, 1)
arr2 = np.array([1, 2, 3])
arr2.shape
# (3,)
arr1 + arr2
# 结果是:
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])上述代码中,数组 arr1 是 4 行 1 列,arr2 是 1 行 3 列。这两个数组要进行相加,按照广播机制会对数组 arr1 和 arr2 都进行扩展,使得数组 arr1 和 arr2 都变成 4 行 3 列。
下面通过一张图来描述广播机制扩展数组的过程:
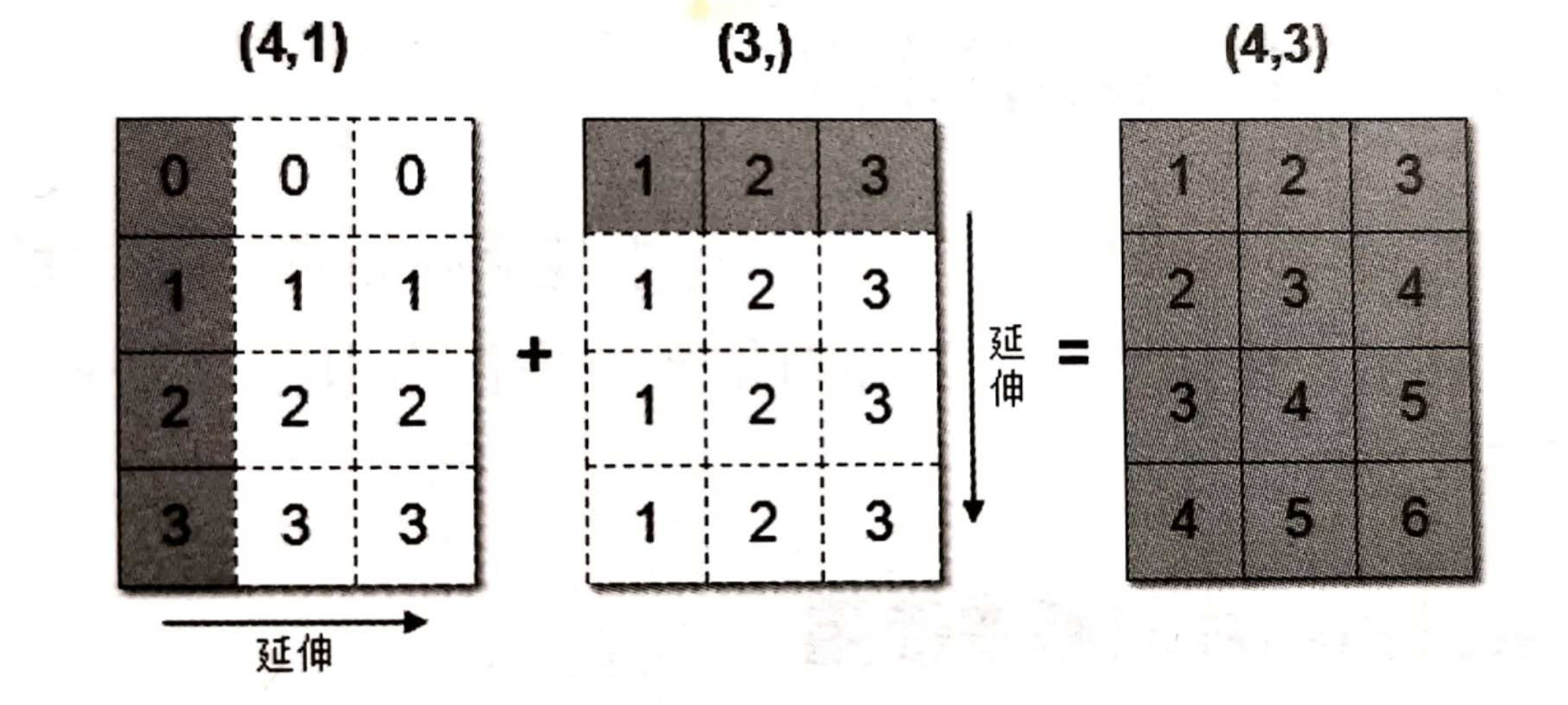
广播机制实现了时两个或两个以上数组的运算,即使这些数组的 shape 不是完全相同的,只需要满足如下任意一个条件即可。
- 数组的某一维度等长。
- 其中一个数组的某一维度为 1。
广播机制需要 扩展维度小的数组,使得它与维度最大的数组的 shape 值相同,以便使用元素级函数或者运算符进行运算。
思考:下面两个 ndarray 是否能够进行运算?
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1], [3]])通用函数
一元函数
| 函数名 | 描述 |
|---|---|
| abs、fabs | 逐个元素地计算整数、浮点数或复数地绝对值 |
| sqrt | 计算每个元素的平方根 (与 arr ** 0.5 相等) |
| square | 计算每个元素地平方 (与 arr ** 2 相等) |
| exp | 计算每个元素的自然指数值 e^x 次方 |
| log、log10、log2、log1p | 分别对应 (自然指数 (e 为底)、对数 10 为底、对数 2 为底、log(1+x)) |
| sign | 计算每个元素的符号值:1(正数)、0(0)、-1(负数) |
| ceil | 计算每个元素的最高整数值 (即大于等于给定数值的最小整数) |
| floor | 计算每个元素的最小整数值 (即小于等于给定整数的最大整数) |
| rint | 将元素保留到整数位,并保持 dtype |
| modf | 分别将数组的小数部分与整数部分按数组形式返回 |
| isnan | 返回数组元素是否是一个 NaN(非数值),形式为布尔值数组 |
| isfinite、isinf | 分别返回数组中的元素是否有限 (非 inf、非 NaN)、是否无限的,形式为布尔值数组 |
| cos、cish、sin、 | 常规三角函数及双曲三角函数 |
| sinh、tan、tanh | |
| arccos、arccosh、arcsin、 | 反三角函数 |
| arcsinh、arctan、arctanh | |
| logical_not | 对数组元素按位取反(~) |
二元通用函数
| 函数名 | 描述 |
|---|---|
| add | 将数组的对应元素相加 |
| subtract | 在第二个数组中,将第一个数组中包含的元素去除 |
| multiply | 将数组的对应元素相乘 |
| divide,floor_divide | 除或整除 (放弃余数) |
| power | 将第二个数组的元素作为第一个数组对应元素的幂次方 |
| maximum | 逐个元素计算最大值,fmax 忽略 NaN |
| minimum | 逐个元素计算最小值,fmin 忽略 NaN |
| mod | 按元素的求模计算 (即求除法的余数) |
| copysign | 将第一个数组的符号值改为第二个数组的符号值 |
| greater,greater_equal,less, | 进行逐个元素的比较,返回布尔值数组(与数学操作符>,>=,<,<=,==,!=x 效果一致) |
| less_equal,equal,not_equal | (接上) |
| logical_and,logical_or | 进行逐个元素的逻辑操作 (与逻辑操作符&、丨、^效果一致) |
| logical_xor |
聚合函数
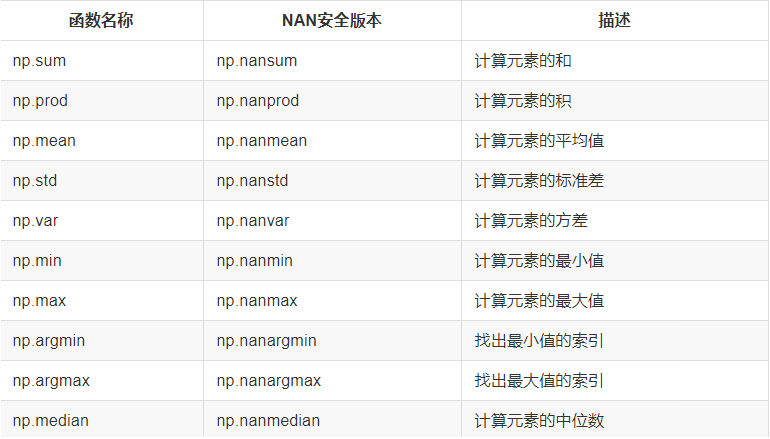
布尔数组函数
| 函数名 | 描述 |
|---|---|
| any | 验证任意一个数据是否为真 |
| all | 验证所有元素为真 |
更多:https://docs.scipy.org/doc/numpy/reference/index.html
附录
文件操作
保存文件
arr2 = np.random.randint(1, 10, size=(5, 4))
# 指定分隔符保存
np.savetxt('a.csv', arr2, fmt='%d', delimiter=',')读取文件
arr3 = np.loadtxt('a.csv', dtype=np.int, delimiter=',')
arr3Axis 理解
之前的课程中,为了方便大家理解,我们说axis=0代表的是行,axis=1代表的是列。但其实不是这么简单理解的。这里我们专门用一节来解释一下这个 axis轴的概念。
简单来说, 最外面的括号代表着 axis=0,依次往里的括号对应的 axis 的计数就依次加 1。什么意思呢?下面再来解释一下。
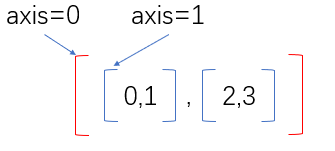
最外面的括号就是axis=0,里面两个子括号axis=1。 **操作方式:如果指定轴进行相关的操作,那么他会使用轴下的每个直接子元素的第 0 个,第 1 个,第 2 个 ... 分别进行相关的操作。 **
现在我们用刚刚理解的方式来做几个操作。比如现在有一个二维的数组:
x = np.array([[0, 1], [2, 3]])求
x数组在axis=0和axis=1两种情况下的和:python>>> x.sum(axis=0) array([2, 4])为什么得到的是[2,4]呢,原因是我们按照
axis=0的方式进行相加,那么就会把**最外面轴下的所有直接子元素中的第 0 个位置进行相加,第 1 个位置进行相加 ... 依此类推 **,得到的就是0+2以及2+3,然后进行相加,得到的结果就是[2,4]。python>>> x.sum(axis=1) array([1, 5])因为我们按照
axis=1的方式进行相加,那么就会把轴为 1 里面的元素拿出来进行求和,得到的就是0,1,进行相加为1,以及2,3进行相加为5,所以最终结果就是[1,5]了。用
np.max求axis=0和axis=1两种情况下的最大值:python>>> np.random.seed(100) >>> x = np.random.randint(0,10,size=(3,5)) >>> x.max(axis=0) array([8, 8, 3, 7, 8])因为我们是按照
axis=0进行求最大值,那么就会在最外面轴里面找直接子元素,然后将每个子元素的第 0 个值放在一起求最大值,将第 1 个值放在一起求最大值,以此类推。而如果axis=1,那么就是拿到每个直接子元素,然后求每个子元素中的最大值:python>>> x.max(axis=1) array([8, 5, 8])用
np.delete在axis=0和axis=1两种情况下删除元素:python>>> np.delete(x,0,axis=0) array([[2, 3]])np.delete是个例外。我们按照axis=0的方式进行删除,那么他会首先找到最外面的括号下的直接子元素中的第 0 个,然后删掉,剩下最后一行的数据。python>>> np.delete(x,0,axis=1) array([[1], [3]])同理,如果我们按照
axis=1进行删除,那么会把第一列的数据删掉。
三维以上数组
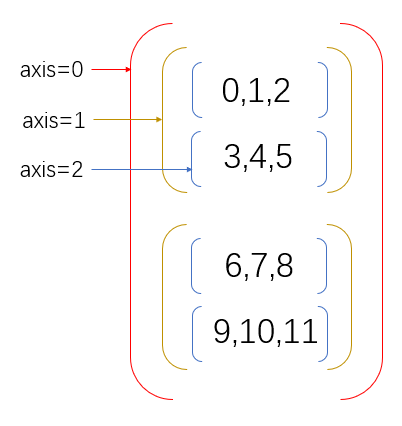
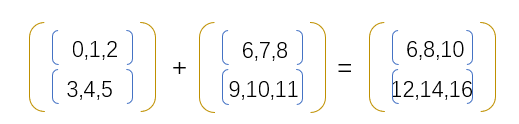
按照之前的理论,如果以上数组按照axis=0的方式进行相加,得到的结果如下:
如果是按照axis=1的方式进行相加,得到的结果如下:
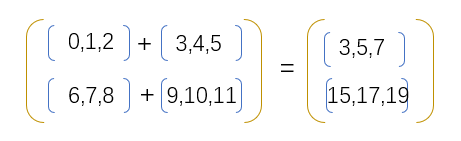
NAN 和 INF 值处理
首先我们要知道这两个英文单词代表的什么意思:
NAN:Not A number,不是一个数字的意思,但是他是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型。INF:Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为 0 的时候为无穷大。比如2/0。
NAN 一些特点:
- NAN 和 NAN 不相等。比如
np.NAN != np.NAN这个条件是成立的。 - NAN 和任何值做运算,结果都是 NAN。
有些时候,特别是从文件中读取数据的时候,经常会出现一些缺失值。缺失值的出现会影响数据的处理。因此我们在做数据分析之前,先要对缺失值进行一些处理。处理的方式有多种,需要根据实际情况来做。一般有两种处理方式:删除缺失值,用其他值进行填充。
删除缺失值:
有时候,我们想要将数组中的NAN删掉,那么我们可以换一种思路,就是只提取不为NAN的值。示例代码如下:
import numpy as np
# 1. 删除所有 NAN 的值,变成一维数组
arr2 = np.random.randint(0, 10, size=(3, 5)).astype(np.float)
# 将第 (0,1) 和 (1,2) 两个值设置为 NAN
arr2[[0, 1], [1, 2]] = np.nan
print('arr2:\n', arr2)
# 此时的 data 会没有 nan,并且变成一个 1 维数组
arr3 = arr2[~np.isnan(arr2)]
print('arr3:\n', arr3)
# 2. 删除 NAN 所在的行
# 获取哪些行有 NAN
lines = np.where(np.isnan(arr2))[0]
print('lines:', lines)
# 使用 delete 方法删除指定的行,axis=0 表示删除行,lines 表示删除的行号
arr4 = np.delete(arr2, lines, axis=0)
print('arr4:\n', arr4)用其他值进行替代:
有些时候我们不想直接删掉,比如有一个成绩表,分别是数学和英语,但是因为某个人在某个科目上没有成绩,那么此时就会出现 NAN 的情况,这时候就不能直接删掉了,就可以使用某些值进行替代。假如有以下表格:
| 数学 | 英语 |
|---|---|
| 59 | 89 |
| 90 | 32 |
| 78 | 45 |
| 34 | NAN |
| NAN | 56 |
| 23 | 56 |
数学,英语
59 ,89
90 ,32
78 ,45
34 ,
,56
23 ,56如果想要求每门成绩的总分,以及每门成绩的平均分,那么就可以采用某些值替代。比如求总分,那么就可以把 NAN 替换成 0, 如果想要求平均分,那么就可以把 NAN 替换成其他值的平均值。示例代码如下:
import numpy as np
scores = np.loadtxt("nan_scores.csv", skiprows=1, delimiter=",", encoding="utf-8", dtype=str)
scores[scores == ""] = np.NAN
scores = scores.astype(float)
# 1. 求出学生成绩的总分
scores1 = scores.copy()
print(scores1.sum(axis=1))
# 2. 求出每门成绩的平均分
scores2 = scores.copy()
for x in range(scores2.shape[1]):
score = scores2[:, x]
print('score:', score)
non_nan_score = score[score == score]
print('non_nan_score:', non_nan_score)
score[score != score] = non_nan_score.mean()
print(scores2.mean(axis=0))随机数组模块(了解)
np.random 模块
正态分布
a. 什么是正态分布
正态分布是一种概率分布。正态分布是具有两个参数μ和σ的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ是此随机变量的标准差,所以正态分布记作 N(μ,σ )。
b. 正态分布的应用
生活、生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。
c. 正态分布特点
μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1 时的正态分布是标准正态分布。
标准差如何来?
方差
是在概率论和统计方差衡量一组数据时离散程度的度量
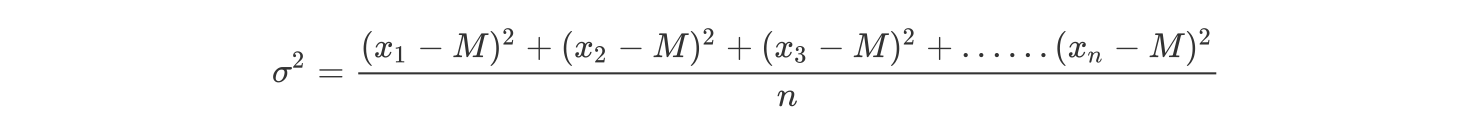
其中 M 为平均值,n 为数据总个数,σ 为标准差,
可以理解一个整体为方差 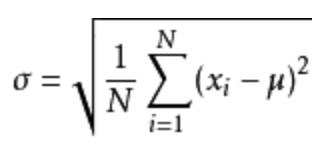
标准差与方差的意义
可以理解成数据的一个离散程度的衡量
正态分布创建
np.random.randn(d0, d1, …, dn)功能:从标准正态分布中返回一个或多个样本值
np.random.normal(loc=0.0, scale=1.0, size=None)loc:float 此概率分布的均值(对应着整个分布的中心 centre)scale:float 此概率分布的标准差(对应于分布的宽度,scale 越大越矮胖,scale 越小,越瘦高)size:int or tuple of ints 输出的 shape,默认为 None,只输出一个值np.random.standard*normal(_size=None)返回指定形状的标准正态分布的数组。
举例 1:生成均值为 1.75,标准差为 1 的正态分布数据,100000000 个
# 生成均值为 1.75,标准差为 1 的正态分布数据
x1 = np.random.normal(1.75, 1, 100000)绘制图像
import matplotlib.pyplot as plt
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2. 绘制图像
plt.hist(x1, 1000)
# 3. 显示图像
plt.show()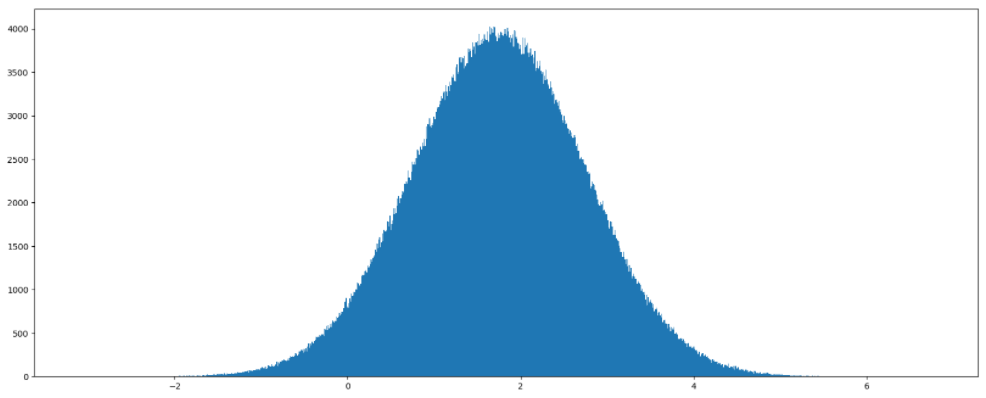
均匀分布
np.random.rand(d0, d1, ..., dn)- 返回**[0.0,1.0)**内的一组均匀分布的数。
np.random.uniform(low=0.0, high=1.0, size=None)- 功能:从一个均匀分布 [low,high) 中随机采样,注意定义域是左闭右开,即包含 low,不包含 high.
- 参数介绍:
- low: 采样下界,float 类型,默认值为 0;
- high: 采样上界,float 类型,默认值为 1;
- size: 输出样本数目,为 int 或元组 (tuple) 类型,例如,size=(m,n,k), 则输出
m*n*k个样本,缺省时输出 1 个值。
- 返回值:ndarray 类型,其形状和参数 size 中描述一致。
np.random.randint(low, high=None, size=None, dtype='l')- 从一个均匀分布中随机采样,生成一个整数或 N 维整数数组
- 取数范围:若 high 不为 None 时,取
[low,high)之间随机整数,否则取值[0,low)之间随机整数。
# 生成均匀分布的随机数
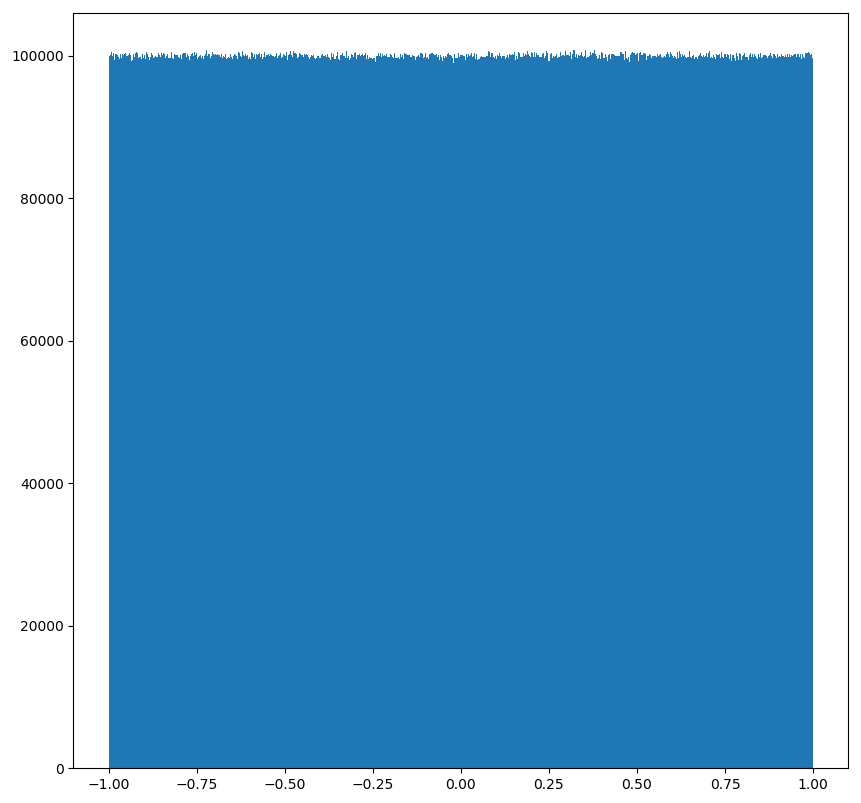
x2 = np.random.uniform(-1, 1, 100000000)画布查看分布状况:
import matplotlib.pyplot as plt
import numpy as np
# 生成均匀分布的随机数
x2 = np.random.uniform(-1, 1, 100000000)
# 画图看分布状况
# 1)创建画布
plt.figure(figsize=(10, 10), dpi=100)
# 2)绘制直方图
plt.hist(x=x2, bins=1000) # x 代表要使用的数据,bins 表示要划分区间数
# 3)显示图像
plt.show()