数据清洗
数据科学家 80% 时间都花费在了这些清洗任务上
有了数据就可以直接进行分析了吗?肯定不是的。
在数据挖掘中,数据清洗就是这样的前期准备工作。对于数据科学家来说,我们会遇到各种各样的数据,在分析前,要投入大量的时间和精力把数据“ 整理裁剪”成自己想要或需要的样子。
为什么呢?因为我们采集到的数据往往有很多问题。
我们先看一个例子,假设老板给你以下的数据,让你做数据分析,你看到这个数据后有什么感觉呢?
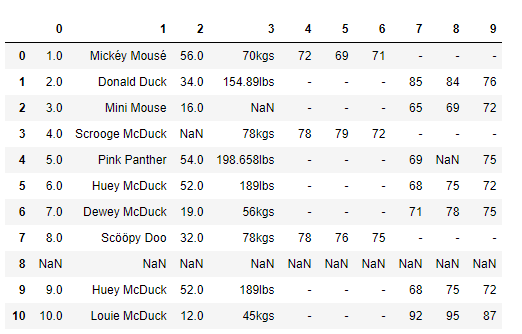
你刚看到这些数据可能会比较懵,因为这些数据缺少标注。
我们在收集整理数据的时候,一定要对数据做标注,数据表头很重要。比如这份数据表,就缺少列名的标注,这样一来我们就不知道每列数据所代表的含义,无法从业务中理解这些数值的作用,以及这些数值是否正确。但在实际工作中,也可能像这个案例一样,数据是缺少标注的。
数据质量的准则
在上面这个服装店会员数据的案例中,一看到这些数据,你肯定能发现几个问题。你是不是想知道,有没有一些准则来规范这些数据的质量呢?
准则肯定是有的。不过如果数据存在七八种甚至更多的问题,我们很难将这些规则都记住。有研究说一个人的短期记忆,最多可以记住 7 条内容或信息,超过 7 条就记不住了。而数据清洗要解决的问题,远不止 7 条,我们万一漏掉一项该怎么办呢?有没有一种方法,我们既可以很方便地记住,又能保证我们的数据得到很好的清洗,提升数据质量呢?
在这里,我将数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”,下面我来解释下。
- 完整性:单条数据是否存在空值,统计的字段是否完善。
- 全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
- 合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
- 唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
在很多数据挖掘的教学中,数据准则通常会列出来 7~8 项,在这里我们归类成了“完全合一”4 项准则,按照以上的原则,我们能解决数据清理中遇到的大部分问题,使得 数据标准、干净、连续,为后续数据统计、数据挖掘做好准备。如果想要进一步优化数据质量,还需要在实际案例中灵活使用。
处理缺失数据
我们在许多教程里面看到的数据和真实的数据的区别就是真实的数据很少是干净和同质的。更寻常的情况是,很多有意思的数据集都有很多的数据缺失。更复杂的是,不同的数据源可能有着不同指代缺失数据的方式
在本节中,我们会讨论一些对于缺失数据的通用处理方式,介绍 Pandas 如何选择和表示这些数据,展示 Pandas 中用来处理缺失数据的內建工具。在后面部分,我们会将这些缺失数据标示为 null、NaN 或 NA。
缺失值
在数据表或 DataFrame 中有很多识别缺失值的方法。一般情况下可以分为两种:一种方法是通过一个覆盖全局的掩码表示缺失值,另一种方法是用一个标签值(sentinel value)表示缺失值。在掩码方法中,掩码可能是一个与原数组维度相同的完整布尔类型数组,也可能是用一个比特(0 或 1)表示有缺失值的局部状态。
在标签方法中,标签值可能是具体的数据(例如用 -9999 表示缺失的整数),也可能是些极少出现的形式。另外,标签值还可能是更全局的值,比如用 NaN(不是一个数)表示缺失的浮点数
None:Python对象类型的缺失值
Pandas 可以使用的第一种缺失值标签是 None,它是一个 Python 单体对象,经常在代码中表示缺失值。由于 None 是一个 Python 对象,所以不能作为任何 NumPy / Pandas 数组类型的缺失值,只能用于 'object' 数组类型(即由 Python 对象构成的数组):
pythonimport numpy as np # None np_arr = np.array([1, None, 3, 4]) print(np_arr)这里 dtype=object 表示 NumPy 认为由于这个数组是 Python 对象构成的,因此将其类型判断为 object。虽然这种类型在某些情景中非常有用,对数据的任何操作最终都会在 Python 层面完成,但是在进行常见的快速操作时,这种类型比其他原生类型数组要消耗更多的资源
使用 Python 对象构成的数组就意味着如果你对一个包含 None 的数组进行累计操作,如 sum() 或者 min(),那么通常会出现类型错误:
pythonprint(np_arr.sum()) # 报错这就是说,在 Python 中没有定义整数与 None 之间的加法运算。
NaN:数值类型的缺失值
另一种缺失值的标签是 NaN(全称 Not a Number,不是一个数字),一种特殊浮点数:
把 NaN 看作是一个数据类病毒——它会将与它接触过的数据同化。无论和 NaN 进行何种操作,最终结果都是 NaN:
pythonnp_arr2 = np.array([1, np.nan, 3, 4]) print(np_arr2) print(np_arr2.sum(), np_arr2.min(), np_arr2.max())NumPy 也提供了一些特殊的累计函数,它们可以忽略缺失值的影响:
pythonprint(np.nansum(np_arr2), np.nanmin(np_arr2), np.nanmax(np_arr2))Pandas中NaN与None的差异
虽然 NaN 与 None 各有各的用处,但是 Pandas 把它们看成是可以等价交换的,在适当的时候会将两者进行替换:
python# NaN 与 None 的差异 ser = pd.Series([1, np.nan, 2, None]) print(ser) """ 0 1.0 1 NaN 2 2.0 3 NaN dtype: float64 """Pandas 会将没有标签值的数据类型自动转换为 NA。例如,当我们将整型数组中的一个值设置为 np.nan 时,这个值就会强制转换成浮点数缺失值 NA。
pythonser2 = pd.Series(range(2), dtype=int) ser2[0] = None print(ser2) """ 0 NaN 1 1.0 dtype: float64 """
Pandas对不同类型缺失值的转换规则
| 类型 | 缺失值转换规则 | NA标签值 |
|---|---|---|
| floating 浮点型 | 无变化 | np.nan |
| object 对象类型 | 无变化 | None 或 np.nan |
| integer 整数类型 | 强制转换为 float64 | np.nan |
| boolean 布尔类型 | 强制转换为 object | None 或 np.nan |
需要注意的是,Pandas 中字符串类型的数据通常是用 object 类型。
处理缺失数据
Pandas 基本上把 None 和 NaN 看成是可以等价交换的缺失值形式。为了完成这种交换过程,Pandas 提供了一些方法来发现、剔除、替换数据结构中的缺失值,主要包括以下几种。
| 方法 | 说明 |
|---|---|
| isnull() | 创建一个布尔类型的掩码标签缺失值。 |
| notnull() | 与 isnull() 操作相反。 |
| dropna() | 返回一个剔除缺失值的数据。 |
| fillna() | 返回一个填充了缺失值的数据副本。 |
判断空值
Pandas 数据结构有两种有效的方法可以发现缺失值:isnull() 和 notnull()。每种方法都返回布尔类型的掩码数据,例如:
import pandas as pd
import numpy as np
# 判断缺失值
ser = pd.Series([1, np.nan, 'hello', None])
print('空值索引:\n', ser.isnull())
print('非空值索引:\n', ser.notnull())
print('空值:\n', ser[ser.isnull()])在 Series 里使用的 isnull() 和 notnull() 同样适用于 DataFrame,产生的结果同样是布尔类型。
剔除缺失值
除了前面介绍的掩码方法,还有两种很好用的缺失值处理方法,分别是 dropna()(剔除缺失值)和 fillna()(填充缺失值)。在 Series 上使用这些方法非常简单:
# 去除缺失值
print('删除空值:\n', ser.dropna())而在 DataFrame 上使用它们时需要设置一些参数,例如下面的 DataFrame:
import pandas as pd
import numpy as np
df = pd.DataFrame(data=[[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])我们没法从 DataFrame 中单独剔除一个值,要么是剔除缺失值所在的整行,要么是整列。根据实际需求,有时你需要剔除整行,有时可能是整列,DataFrame 中的 dropna() 会有一些参数可以配置。
默认情况下,dropna() 会剔除任何包含缺失值的整行数据:
"""删除缺失值"""
print(df)
print('默认删除空行:\n', df.dropna())可以设置按不同的坐标轴剔除缺失值,比如 axis=1(或 axis='columns')会剔除任何包含缺失值的整列数据:
# 删除空列
print('默认删除空行:\n', df.dropna())
print('删除空列:\n', df.dropna(axis='columns'))但是这么做也会把非缺失值一并剔除,因为可能有时候只需要剔除全部是缺失值的行或列,或者绝大多数是缺失值的行或列。这些需求可以通过设置 how 或 thresh 参数来满足,它们可以设置剔除行或列缺失值的数量阈值。
默认设置是 how='any',也就是说只要有缺失值就剔除整行或整列(通过 axis 设置坐标轴)。你还可以设置 how='all' ,这样就只会剔除全部是缺失值的行或列了:
print('行列均为空的时候才删除:\n', df.dropna(axis='columns', how='all'))还可以通过 thresh 参数设置行或列中非缺失值的最小数量,从而实现更加个性化的配置:
print('删除两个以上空值的行数:\n', df.dropna(thresh=2))并且可以指定列进行剔除
print('指定列删除空值:\n', df.dropna(subset=[1, 2]))
print('指定列删除空值:\n', df.dropna(subset=[1]))**填充缺失值 **
有时候你可能并不想移除缺失值,而是想把它们替换成有效的数值。有效的值可能是像 0、1、2 那样单独的值,也可能是经过填充(imputation)或转换(interpolation)得到的。虽然你可以通过 isnull() 方法建立掩码来填充缺失值,但是 Pandas 为此专门提供了一个 fillna() 方法,它将返回填充了缺失值后的数组副本。
来用下面的 Series 演示:
import pandas as pd
import numpy as np
"""填充缺失值"""
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list("ABCD"))我们将用一个单独的值来填充缺失值,例如用 0,也可以用缺失值前面的有效值来从前往后填充(forward-fill)与从后往前填充(back-fill)
print(df)
print('使用 0 填充缺失值:\n', df.fillna(0))
print('从前往后填充:\n', df.fillna(method="ffill"))
print('后往前填充:\n', df.fillna(method="bfill"))如果需要列填充,只是在填充时需要设置坐标轴参数 axis:
"""可以修改填充轴"""
print('列填充:\n', df.fillna(method='ffill', axis=1))并且可以自定义指定列进行填充
values = {"A": 0, "B": 1, "C": 2, "D": 3}
print('指定列进行填充:\n', df.fillna(value=values))
print('只填充一个:\n', df.fillna(value=values, limit=1))重复数据
| 方法 | 说明 |
|---|---|
| duplicated() | 返回布尔型 Series 表示每行是否为重复行 |
| drop_duplicates() | 删除重复数据 |
处理重复数据
示例代码:
import numpy as np
import pandas as pd
"""重复行"""
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5, 5]
})
# 判断重复行,默认保留第一个
print(df.duplicated())
# 判断重复行,保留最后一个
print('保留最后一个:\n', df.duplicated(keep='last'))
# 所有的重复行全部标注出来
print('全部标注:\n', df.duplicated(keep=False))
# 获取指定列的重复行
print('指定列:\n', df.duplicated(subset=['brand']))过滤重复行
drop_duplicates()
- 默认判断全部列
- 可指定按某些列判断
示例代码:
print(df_obj.drop_duplicates())
print(df_obj.drop_duplicates('data2'))运行结果:
# print(df_obj.drop_duplicates())
data1 data2
0 a 3
1 a 2
4 b 1
5 b 0
6 b 3
# print(df_obj.drop_duplicates('data2'))
data1 data2
0 a 3
1 a 2
4 b 1
5 b 0问题 1:一列有多个参数
在数据中不难发现,姓名列(Name)包含了两个参数 Firtname 和 Lastname。为了达到数据整洁目的,我们将 Name 列拆分成 Firstname 和 Lastname 两个字段。我们使用 Python 的 split 方法,str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除。
# 切分名字,删除源数据列
df[['first_name', 'last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)问题 2:重复数据
我们校验一下数据中是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
# 删除重复数据行
df.drop_duplicates(['first_name', 'last_name'], inplace=True)这样,我们就将上面案例中的会员数据进行了清理,来看看清理之后的数据结果。怎么样?是不是又干净又标准?
数据替换
替换值
replace 根据值的内容进行替换
示例代码:
import pandas as pd
df = pd.DataFrame({'A': [0, 1, 2, 3, 4],
'B': [5, 6, 7, 8, 9],
'C': ['a', 'b', 'c', 'd', 'e']})
print(df)
# 替换一个值
print('替换一个值:\n', df.replace(0, 5))
# 列表替换
print('列表替换:\n', df.replace([0, 5, 'b'], 4))
print('列表替换:\n', df.replace(['b', 'c'], [10, 11]))
# 字典替换
# 值替换
print('字典替换:\n', df.replace({0: 10, 1: 100, 'a': 100}))
# 指定替换位置的元素
print('字典替换:\n', df.replace({'A': 0, 'B': 5}, 100))
# 只替换 a 列
print('字典替换 3:\n', df.replace({'A': {0: 100, 4: 400, 5: 100}}))正则替换
import pandas as pd
"""正则表达式替换"""
df = pd.DataFrame({'A': ['bat', 'foo', 'bait'],
'B': ['abc', 'bar', 'xyz']})
print(df)
# 替换内容
print(df.replace(to_replace=r'^ba.$', value='new', regex=True))
# 字典替换
print(df.replace({'A': r'^ba.$'}, {'A': 'new'}, regex=True))
print(df.replace(regex=r'^ba.$', value='new'))
print(df.replace(regex={r'^ba.$': 'new', 'foo': 'xyz'}))
print(df.replace(regex=[r'^ba.$', 'foo'], value='new'))数据转换
map
根据 map 传入的函数对每行或每列进行转换
示例代码:
import pandas as pd
import numpy as np
s = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
print(s)
# 指定字典进行替换,没有指定的内容替换为空
print(s.map({'cat': 'kitten', 'dog': 'puppy'}))
print(s)
# 指定方法进行替换
print(s.map(lambda x: 'I am a {}'.format(x)))
def func(temp):
return 'I am a {}'.format(temp)
# 将缺失值忽略替换
print(s.map(func, na_action='ignore'))apply
apply 将函数应用到列或行上
- apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1 为行进行运算
- 定义一个对列,最大值 - 最小值的函数
df = pd.DataFrame(np.random.randn(5, 4))
df
# apply 将函数应用到行或者列
def f(x): return x.max()
# 默认应用在行上
df.apply(f) # 默认 axis=0# 替换行
print('替换行\n', df.apply(replace_line, axis=1))
# 将返回的行数据进行展开
print('替换行 - 展开\n', df.apply(replace_line, axis=1, result_type='expand'))applymap
applymap 将函数应用到每个数据
"""批量操作数据 针对每一个元素"""
df = pd.DataFrame([[1, 2.12], [3.356, 4.567]])
print(df)
print(df.applymap(lambda x: '%.2f' % x))字符串操作
字符串方法


问题:列数据的单位不统一
观察 weight 列的数值,我们能发现 weight 列的单位不统一。有的单位是千克(kgs),有的单位是磅(lbs)。
这里我使用千克作为统一的度量单位,将磅(lbs)转化为千克(kgs):
import pandas as pd
df = pd.read_csv('taobao_data.csv', encoding='utf-8')
df = df.drop(['缩略图', '标题链接'], axis=1)
df['deal-cnt'] = df['deal-cnt'].str.strip('人收货')
rows_with_w = df['deal-cnt'].str.contains('万+').fillna(False)
print(rows_with_w)
print(df[rows_with_w])
for i, row in df[rows_with_w].iterrows():
print(f'i {i} row {row}')
weight = int(float(row['deal-cnt'].strip('万+'))) * 10000
df.at[i, 'deal-cnt'] = '{}'.format(weight)
print(df)问题:非 ASCII 字符
我们可以看到在数据集中 Fristname 和 Lastname 有一些非 ASCII 的字符。我们可以采用删除或者替换的方式来解决非 ASCII 问题,这里我们使用删除方法:
# 删除非 ASCII 字符
df['first_name'].replace({r'[^\x00-\x7F]+': ''}, regex=True, inplace=True)
df['last_name'].replace({r'[^\x00-\x7F]+': ''}, regex=True, inplace=True)正则表达式方法

pandas 字符串函数: