分组聚合
数据聚合与分组
简单的累计方法可以让我们对数据集有一个笼统的认识,但是我们经常还需要对某些标签或索引的局部进行累计分析,这时就需要用到 groupby 了。虽然“分组”(group by)这个名字是借用 SQL 数据库语言的命令,但其理念引用发明 R 语言 frame 的 Hadley Wickham 的观点可能更合适:分割(split)、应用(apply)和组合(combine)。
分割、应用和组合
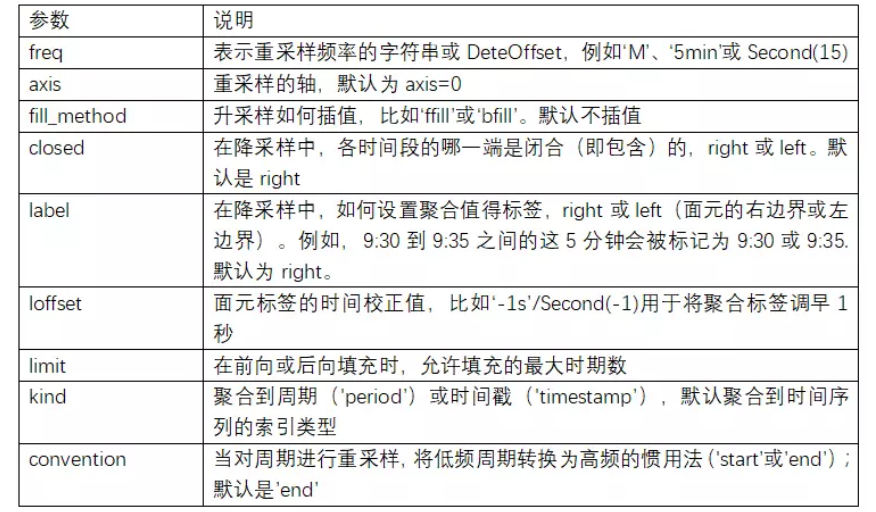
一个经典分割 - 应用 - 组合操作,其中“apply”的 是一个求和函数。
下图清晰地描述了 GroupBy 的过程。分割步骤将 DataFrame 按照指定的键分割成若干组。应用步骤对每个组应用函数,通常是累计、转换或过滤函数。 组合步骤将每一组的结果合并成一个输出数组。
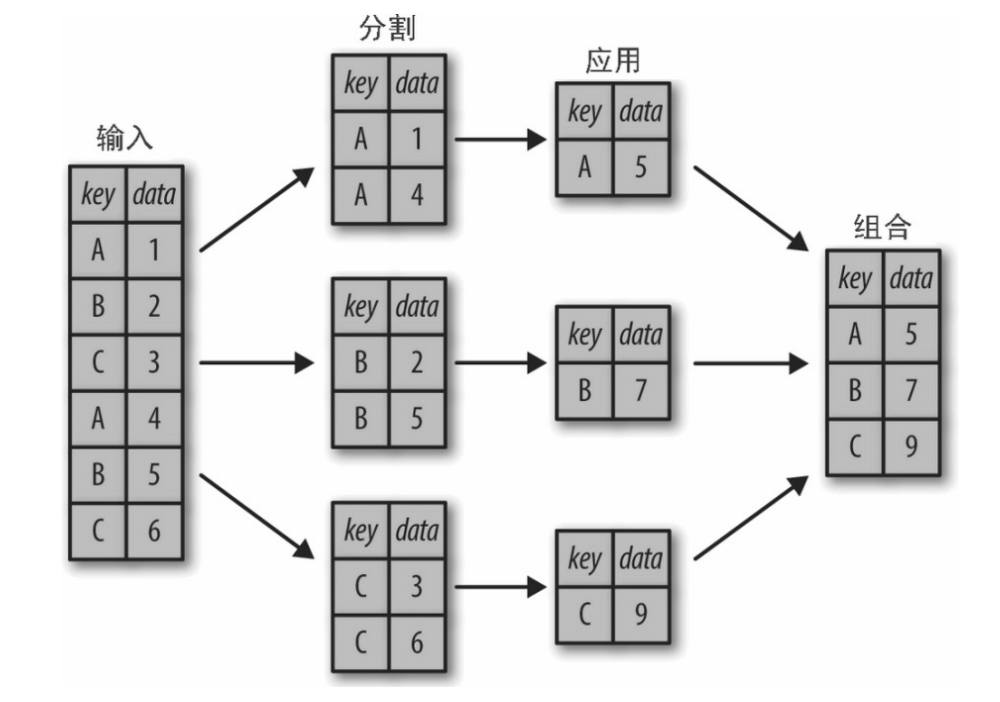
虽然我们也可以通过前面介绍的一系列的掩码、累计与合并操作来实现,但是意识到中间分割过程不需要显式地暴露出来这一点十分重要。而且 GroupBy(经常)只需要一行代码,就可以计算每组的和、均值、计数、最小值以及其他累计值。GroupBy 的用处就是将这些步骤进行抽象:用户不需要知道在底层如何计算,只要把操作看成一个整体就够了。
groupby:(by=None,as_index=True)
by:根据什么进行分组,用于确定 groupby 的组as_index:对于聚合输出,返回以组便签为索引的对象,仅对 DataFrame
import pandas as pd
df = pd.DataFrame({'fruit': ['apple', 'banana', 'orange', 'apple', 'banana'],
'color': ['red', 'yellow', 'yellow', 'cyan', 'cyan'],
'price': [8.5, 6.8, 5.6, 7.8, 6.4],
'count': [3, 4, 6, 5, 2]})
df['total'] = df['price'] * df['count']
print(df)需要注意的是,这里的返回值不是一个 DataFrame 对象,而是一 个 DataFrameGroupBy 对象。这个对象的魔力在于,你可以将它 看成是一种特殊形式的 DataFrame,里面隐藏着若干组数据,但是在没有应用累计函数之前不会计算。这种“延迟计算”(lazy evaluation)的方法使得大多数常见的累计操作可以通过一种对用户而言几乎是透明的(感觉操作仿佛不存在)方式非常高效地实现。
为了得到这个结果,可以对 DataFrameGroupBy 对象应用累计函数,它会完成相应的应用 / 组合步骤并生成结果:
print(df.groupby('fruit').sum())
"""
price
fruit
apple 16.3
banana 13.2
orange 5.6
"""sum() 只是众多可用方法中的一个。你可以用 Pandas 或 NumPy 的任意一种累计函数,也可以用任意有效的 DataFrame 对象。
GroupBy 对象
GroupBy 对象是一种非常灵活的抽象类型。在大多数场景中,你可以将它看成是 DataFrame 的集合,在底层解决所有难题。让我们用行星数据来做一些演示。
GroupBy 中最重要的操作可能就是 aggregate、filter、transform 和 apply(累计、过滤、转换、应用)了,后文将详细介绍这些内 容,现在先来介绍一些 GroupBy 的基本操作方法。
(1) 按列取值。GroupBy 对象与 DataFrame 一样,也支持按列取 值,并返回一个修改过的 GroupBy 对象,例如:
import pandas as pd
df = pd.DataFrame({'fruit': ['apple', 'banana', 'orange', 'apple', 'banana'],
'color': ['red', 'yellow', 'yellow', 'cyan', 'cyan'],
'price': [8.5, 6.8, 5.6, 7.8, 6.4],
'count': [3, 4, 6, 5, 2]})
df['total'] = df['price'] * df['count']
# 查看类型
print(df.groupby('fruit'))
print(df.groupby('fruit').sum())
"""group 对象"""
for name, group in df.groupby('fruit'):
print('分组名:\t', name) # 输出组名
print('分组数据:\n', group) # 输出数据块
# 对数量与总价
print(df.groupby('fruit')[['count', 'total']].apply(lambda x: x.sum()))聚合(agg)
| 函数名 | 描述 |
|---|---|
| count | 分组中非 NA 值的数量 |
| sum | 非 NA 值的和 |
| mean | 非 NA 值的平均值 |
| median | 非 NA 值的中位数 |
| std, var | 标准差和方差 |
| min, max | 非 NA 的最小值,最大值 |
| prod | 非 NA 值的乘积 |
| first, last | 非 NA 值的第一个,最后一个 |
"""累计"""
# 多分组数据进行多个运算
print(df.groupby('fruit').aggregate(['min', np.median, max]))
print(df.groupby('fruit').aggregate({'price': 'min', 'count': 'max'}))
"""
如果我现在有个需求,计算每种水果的差值,
1. 上表中的聚合函数不能满足于我们的需求,我们需要使用自定义的聚合函数
2. 在分组对象中,使用我们自定义的聚合函数
"""
# 定义一个计算差值的函数
def diff_value(arr): return arr.max() - arr.min()
print(df.groupby('fruit')['price'].agg(diff_value))过滤(filter)
"""过滤"""
def filter_func(x):
# 获取标准差大于 4 的值
# print('price:\t', [x['price']])
# print('price:\t', type(x['price']))
# print('price:\t', x['price'].mean())
return x['price'].mean() > 6 # 平均价格大四
print(df)
print(df.groupby('fruit').mean())
print(df.groupby('fruit').filter(filter_func))
"""转换"""
print(df.groupby('fruit').transform(lambda x: x - x.mean()))数据合并(知道)
数据合并 (pd.merge)
根据单个或多个键将不同 DataFrame 的行连接起来
类似数据库的连接操作
pd.merge:(left, right, how='inner',on=None,left_on=None, right_on=None)left: 合并时左边的 DataFrameright: 合并时右边的 DataFramehow: 合并的方式,默认 'inner', 'outer', 'left', 'right'on: 需要合并的列名,必须两边都有的列名,并以 left 和 right 中的列名的交集作为连接键left_on: left Dataframe 中用作连接键的列right_on: right Dataframe 中用作连接键的列内连接
inner:对两张表都有的键的交集进行联合
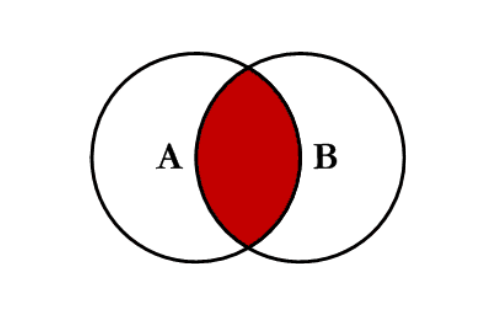
- 全连接
outer:对两者表的都有的键的并集进行联合
- 左连接
left:对所有左表的键进行联合
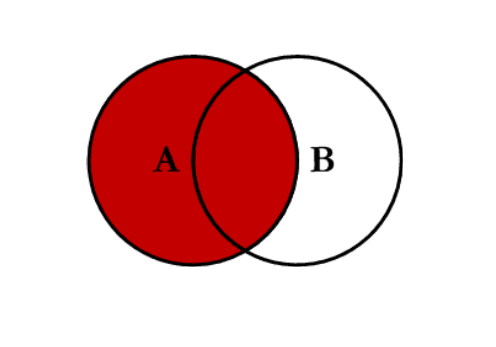
- 右连接
right:对所有右表的键进行联合
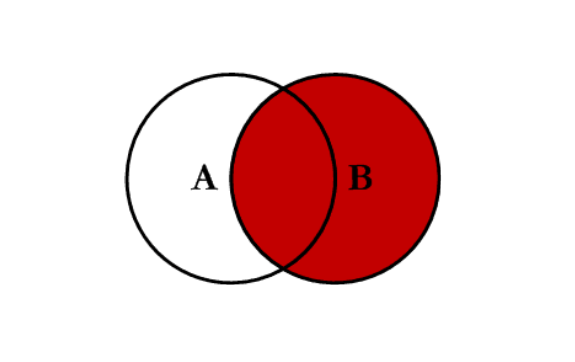
示例代码:
import pandas as pd
import numpy as np
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, on='key') # 指定连接键 key运行结果:
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3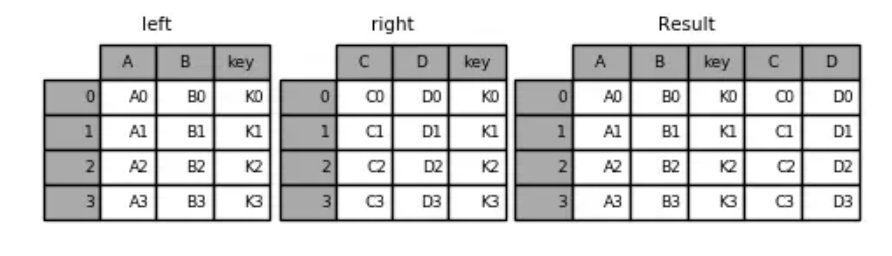
示例代码:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, on=['key1', 'key2']) # 指定多个键,进行合并运行结果:
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2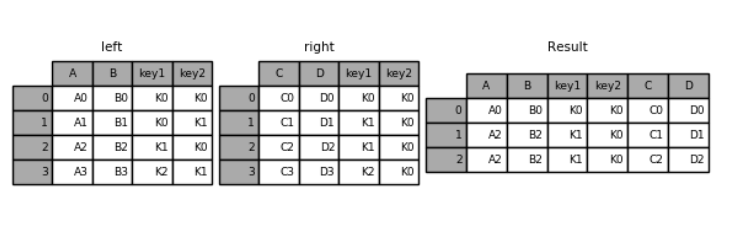
#指定左连接
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how='left', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN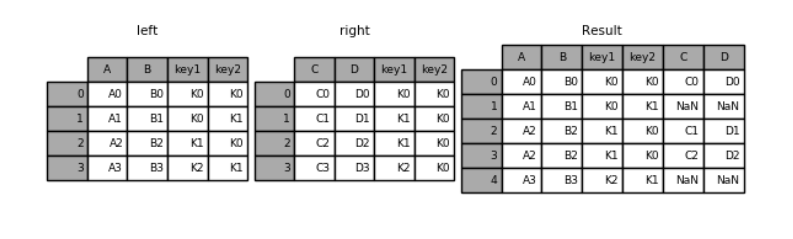
#指定右连接
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how='right', on=['key1', 'key2'])
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K1 K0 A2 B2 C1 D1
2 K1 K0 A2 B2 C2 D2
3 K2 K0 NaN NaN C3 D3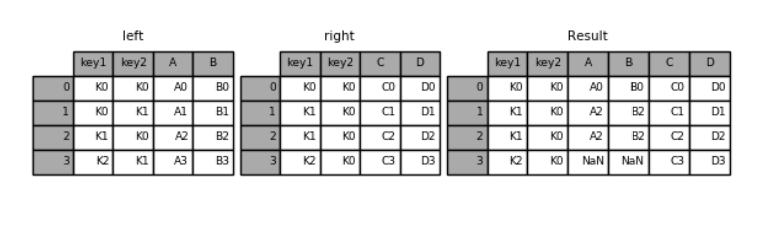
默认是“内连接”(inner),即结果中的键是交集
how 指定连接方式
“外连接”(outer),结果中的键是并集
示例代码:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left,right,how='outer',on=['key1','key2'])运行结果:
key1 key2 A B C D
0 K0 K0 A0 B0 C0 D0
1 K0 K1 A1 B1 NaN NaN
2 K1 K0 A2 B2 C1 D1
3 K1 K0 A2 B2 C2 D2
4 K2 K1 A3 B3 NaN NaN
5 K2 K0 NaN NaN C3 D3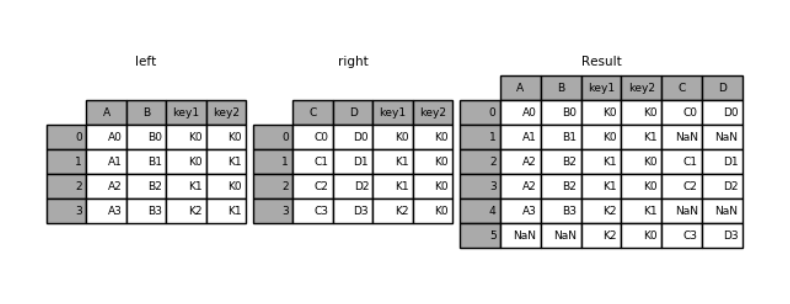
处理重复列名
参数 suffixes:默认为_x, _y
示例代码:
# 处理重复列名
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data': np.random.randint(0, 10, 7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data': np.random.randint(0, 10, 3)})
print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))运行结果:
data_left key data_right
0 9 b 1
1 5 b 1
2 1 b 1
3 2 a 8
4 2 a 8
5 5 a 8按索引连接
参数 left_index=True 或 right_index=True
示例代码:
# 按索引连接
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': np.random.randint(0, 10, 7)})
df_obj2 = pd.DataFrame({'data2': np.random.randint(0, 10, 3)}, index=['a', 'b', 'd'])
print(pd.merge(df_obj1, df_obj2, left_on='key', right_index=True))运行结果:
data1 key data2
0 3 b 6
1 4 b 6
6 8 b 6
2 6 a 0
4 3 a 0
5 0 a 0数据合并 (pd.concat)
沿轴方向将多个对象合并到一起
NumPy 的 concat
np.concatenate
示例代码:
import numpy as np
import pandas as pd
arr1 = np.random.randint(0, 10, (3, 4))
arr2 = np.random.randint(0, 10, (3, 4))
print(arr1)
print(arr2)
print(np.concatenate([arr1, arr2]))
print(np.concatenate([arr1, arr2], axis=1))运行结果:
# print(arr1)
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]]
# print(arr2)
[[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]
# print(np.concatenate([arr1, arr2]))
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]
[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]
# print(np.concatenate([arr1, arr2], axis=1))
[[3 3 0 8 6 8 7 3]
[2 0 3 1 1 6 8 7]
[4 8 8 2 1 4 7 1]]pd.concat
- 注意指定轴方向,默认 axis=0
- join 指定合并方式,默认为 outer
- Series 合并时查看行索引有无重复
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
np.arange(6).reshape(3, 2),
index=list('abc'),
columns=['one', 'two']
)
df2 = pd.DataFrame(
np.arange(4).reshape(2, 2) + 5,
index=list('ac'),
columns=['three', 'four']
)
pd.concat([df1, df2]) # 默认外连接,axis=0
"""
four one three two
a NaN 0.0 NaN 1.0
b NaN 2.0 NaN 3.0
c NaN 4.0 NaN 5.0
a 6.0 NaN 5.0 NaN
c 8.0 NaN 7.0 NaN
"""
pd.concat([df1, df2], axis='columns') # 指定 axis=1 连接
"""
one two three four
a 0 1 5.0 6.0
b 2 3 NaN NaN
c 4 5 7.0 8.0
"""
# 同样我们也可以指定连接的方式为 inner
pd.concat([df1, df2], axis=1, join='inner')
"""
one two three four
a 0 1 5 6
c 4 5 7 8
"""时间序列 (知道)
时间序列(time series)数据是一种重要的结构化数据形式,。在多个时间点观察或测量到的任何时间都可以形成一段时间序列。很多时间, 时间序列是固定频率的,也就是说,数据点是根据某种规律定期出现的(比如每 15 秒。。。。)。时间序列也可以是不定期的。时间序列数据的意义取决于具体的应用场景。主要由以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时期(period),如 2007 年 1 月或 2010 年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例。
时间和日期数据类型
Python 标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到 datetime、time 以及 calendar 模块。datetime.datetime(也可以简写为 datetime)是用得最多的数据类型:
In [10]: from datetime import datetime
In [11]: now = datetime.now()
In [12]: now
Out[12]: datetime.datetime(2017, 9, 25, 14, 5, 52, 72973)
In [13]: now.year, now.month, now.day
Out[13]: (2017, 9, 25)datetime 以毫秒形式存储日期和时间。timedelta 表示两个 datetime 对象之间的时间差:
In [14]: delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15)
In [15]: delta
Out[15]: datetime.timedelta(926, 56700)
In [16]: delta.days
Out[16]: 926
In [17]: delta.seconds
Out[17]: 56700可以给 datetime 对象加上(或减去)一个或多个 timedelta,这样会产生一个新对象:
In [18]: from datetime import timedelta
In [19]: start = datetime(2011, 1, 7)
In [20]: start + timedelta(12)
Out[20]: datetime.datetime(2011, 1, 19, 0, 0)
In [21]: start - 2 * timedelta(12)
Out[21]: datetime.datetime(2010, 12, 14, 0, 0)
字符串和 datetime 的相互转换
利用 str 或 strftime 方法(传入一个格式化字符串),datetime 对象和 pandas 的 Timestamp 对象(稍后就会介绍)可以被格式化为字符串:
In [22]: stamp = datetime(2011, 1, 3)
In [23]: str(stamp)
Out[23]: '2011-01-03 00:00:00'
In [24]: stamp.strftime('%Y-%m-%d')
Out[24]: '2011-01-03'时间序列
| 代码 | 含义 | 时间范围 (相对) | 时间范围 (绝对) |
|---|---|---|---|
Y | 年 | ± 9.2e18 年 | [公元前 9.2e18 至 公元后 9.2e18] |
M | 月 | ± 7.6e17 年 | [公元前 7.6e17 至 公元后 7.6e17] |
W | 星期 | ± 1.7e17 年 | [公元前 1.7e17 至 公元后 1.7e17] |
D | 日 | ± 2.5e16 年 | [公元前 2.5e16 至 公元后 2.5e16] |
h | 小时 | ± 1.0e15 年 | [公元前 1.0e15 至 公元后 1.0e15] |
m | 分钟 | ± 1.7e13 年 | [公元前 1.7e13 至 公元后 1.7e13] |
s | 秒 | ± 2.9e12 年 | [公元前 2.9e9 至 公元后 2.9e9] |
ms | 毫秒 | ± 2.9e9 年 | [公元前 2.9e6 至 公元后 2.9e6] |
us | 微秒 | ± 2.9e6 年 | [公元前 290301 至 公元后 294241] |
ns | 纳秒 | ± 292 年 | [公元后 1678 至 公元后 2262] |
ps | 皮秒 | ± 106 天 | [公元后 1969 至 公元后 1970] |
fs | 飞秒 | ± 2.6 小时 | [公元后 1969 至 公元后 1970] |
as | 阿秒 | ± 9.2 秒 | [公元后 1969 至 公元后 1970] |
datetime.strptime 可以用这些格式化编码将字符串转换为日期:
In [26]: datetime.strptime(value, '%Y-%m-%d')
Out[26]: datetime.datetime(2011, 1, 3, 0, 0)
In [27]: datestrs = ['7/6/2011', '8/6/2011']
In [28]: [datetime.strptime(x, '%m/%d/%Y') for x in datestrs]
Out[28]:
[datetime.datetime(2011, 7, 6, 0, 0),
datetime.datetime(2011, 8, 6, 0, 0)]datetime.strptime 是通过已知格式进行日期解析的最佳方式。但是每次都要编写格式定义是很麻烦的事情,尤其是对于一些常见的日期格式。这种情况下,你可以用 dateutil 这个第三方包中的 parser.parse 方法(pandas 中已经自动安装好了):
In [29]: from dateutil.parser import parse
In [30]: parse('2011-01-03')
Out[30]: datetime.datetime(2011, 1, 3, 0, 0)dateutil 可以解析几乎所有人类能够理解的日期表示形式:
In [31]: parse('Jan 31, 1997 10:45 PM')
Out[31]: datetime.datetime(1997, 1, 31, 22, 45)在国际通用的格式中,日出现在月的前面很普遍,传入 dayfirst=True 即可解决这个问题:
In [32]: parse('6/12/2011', dayfirst=True)
Out[32]: datetime.datetime(2011, 12, 6, 0, 0)pandas 通常是用于处理成组日期的,不管这些日期是 DataFrame 的轴索引还是列。to_datetime 方法可以解析多种不同的日期表示形式。对标准日期格式(如 ISO8601)的解析非常快:
In [33]: datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00']
In [34]: pd.to_datetime(datestrs)
Out[34]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='dat
etime64[ns]', freq=None)它还可以处理缺失值(None、空字符串等):
In [35]: idx = pd.to_datetime(datestrs + [None])
In [36]: idx
Out[36]: DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dty
pe='datetime64[ns]', freq=None)
In [37]: idx[2]
Out[37]: NaT
In [38]: pd.isnull(idx)
Out[38]: array([False, False, True], dtype=bool)NaT(Not a Time)是 pandas 中时间戳数据的 null 值。
时间序列基础
pandas 最基本的时间序列类型就是以时间戳(通常以 Python 字符串或 datatime 对象表示)为索引的 Series:
In [39]: from datetime import datetime
In [40]: dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),
....: datetime(2011, 1, 7), datetime(2011, 1, 8),
....: datetime(2011, 1, 10), datetime(2011, 1, 12)]
In [41]: ts = pd.Series(np.random.randn(6), index=dates)
In [42]: ts
Out[42]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64这些 datetime 对象实际上是被放在一个 DatetimeIndex 中的:
In [43]: ts.index
Out[43]:
DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
'2011-01-10', '2011-01-12'],
dtype='datetime64[ns]', freq=None)跟其他 Series 一样,不同索引的时间序列之间的算术运算会自动按日期对齐:
In [44]: ts + ts[::2]
Out[44]:
2011-01-02 -0.409415
2011-01-05 NaN
2011-01-07 -1.038877
2011-01-08 NaN
2011-01-10 3.931561
2011-01-12 NaN
dtype: float64ts[::2] 是每隔两个取一个。
索引、选取、子集构造
当你根据标签索引选取数据时,时间序列和其它的 pandas.Series 很像:
In [48]: stamp = ts.index[2]
In [49]: ts[stamp]
Out[49]: -0.51943871505673811还有一种更为方便的用法:传入一个可以被解释为日期的字符串:
In [50]: ts['1/10/2011']
Out[50]: 1.9657805725027142
In [51]: ts['20110110']
Out[51]: 1.9657805725027142日期的范围、频率以及移动
| 码 | 说明 |
|---|---|
| D | 天(calendar day,按日历算,含双 休日)周 |
| W | 周(weekly) |
| M | 月末(month end) |
| Q | 季末(quarter end) |
| A | 年末(year end) |
| H | 小时(hours) |
| T | 分钟(minutes) |
| S | 秒(seconds) |
| L | 毫秒(milliseonds) |
| U | 微秒(microseconds) |
| N | 纳秒(nanoseconds) |
| B | 天(business day,仅含工作日) |
| BM | 月末(business month end,仅含工作日) |
| BQ | 季末(business quarter end,仅含工作日) |
| BA | 年末(business year end,仅含工作日) |
| BH | 小时(business hours,工作时间) |
pandas 中的原生时间序列一般被认为是不规则的,也就是说,它们没有固定的频率。对于大部分应用程序而言,这是无所谓的。但是,它常常需要以某种相对固定的频率进行分析,比如每日、每月、每 15 分钟等(这样自然会在时间序列中引入缺失值)。幸运的是,pandas 有一整套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具。例如,我们可以将之前那个时间序列转换为一个具有固定频率(每日)的时间序列,只需调用 resample 即可:
In [72]: ts
Out[72]:
2011-01-02 -0.204708
2011-01-05 0.478943
2011-01-07 -0.519439
2011-01-08 -0.555730
2011-01-10 1.965781
2011-01-12 1.393406
dtype: float64
In [73]: resampler = ts.resample('D')字符串“D”是每天的意思。
频率的转换(或重采样)是一个比较大的主题。这里,我将告诉你如何使用基本的频率和它的倍数。
生成日期范围
虽然我之前用的时候没有明说,但你可能已经猜到 pandas.date_range 可用于根据指定的频率生成指定长度的 DatetimeIndex:
In [74]: index = pd.date_range('2012-04-01', '2012-06-01')
In [75]: index
Out[75]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')默认情况下,date_range 会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:
In [76]: pd.date_range(start='2012-04-01', periods=20)
Out[76]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
In [77]: pd.date_range(end='2012-06-01', periods=20)
Out[77]:
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27','2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM" 频率(表示 business end of month),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
In [78]: pd.date_range('2000-01-01', '2000-12-01', freq='BM')
Out[78]:
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。并不是所有的重采样都能被划分到这两个大类中。例如,将 W-WED(每周三)转换为 W-FRI 既不是降采样也不是升采样。
pandas 对象都带有一个 resample 方法,它是各种频率转换工作的主力函数。resample 有一个类似于 groupby 的 API,调用 resample 可以分组数据,然后会调用一个聚合函数:
In [208]: rng = pd.date_range('2000-01-01', periods=100, freq='D')
In [209]: ts = pd.Series(np.random.randn(len(rng)), index=rng)
In [210]: ts
Out[210]:
2000-01-01 0.631634
2000-01-02 -1.594313
2000-01-03 -1.519937
2000-01-04 1.108752
2000-01-05 1.255853
2000-01-06 -0.024330
2000-01-07 -2.047939
2000-01-08 -0.272657
2000-01-09 -1.692615
2000-01-10 1.423830
...
2000-03-31 -0.007852
2000-04-01 -1.638806
2000-04-02 1.401227
2000-04-03 1.758539
2000-04-04 0.628932
2000-04-05 -0.423776
2000-04-06 0.789740
2000-04-07 0.937568
2000-04-08 -2.253294
2000-04-09 -1.772919
Freq: D, Length: 100, dtype: float64
In [211]: ts.resample('M').mean()
Out[211]:
2000-01-31 -0.165893
2000-02-29 0.078606
2000-03-31 0.223811
2000-04-30 -0.063643
Freq: M, dtype: float64
In [212]: ts.resample('M', kind='period').mean()
Out[212]:
2000-01 -0.165893
2000-02 0.078606
2000-03 0.223811
2000-04 -0.063643
Freq: M, dtype: float64resample 是一个灵活高效的方法,可用于处理非常大的时间序列。