案例:鸢尾花种类预测
本实验介绍了使用 Python 进行机器学习的一些基本概念。在本案例中,将使用 K-Nearest Neighbor(KNN)算法对鸢尾花的种类进行分类,并测量花的特征。
本案例目的:
- 遵循并理解完整的机器学习过程
- 对机器学习原理和相关术语有基本的了解。
- 了解评估机器学习模型的基本过程。
数据集介绍
Iris 数据集是常用的分类实验数据集,由 Fisher, 1936 收集整理。Iris 也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:

from sklearn.datasets import load_iris
# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值是一个继承自字典的 Bench
print("鸢尾花的特征值:\n", iris["data"])
print("鸢尾花的目标值:\n", iris.target)
print("鸢尾花特征的名字:\n", iris.feature_names)
print("鸢尾花目标值的名字:\n", iris.target_names)
print("鸢尾花的描述:\n", iris.DESCR)查看数据分布
通过创建一些图,以查看不同类别是如何通过特征来区分的。在理想情况下,标签类将由一个或多个特征对完美分隔。在现实世界中,这种理想情况很少会发生。
seaborn 介绍
- Seaborn 是基于 Matplotlib 核心库进行了更高级的 API 封装,可以让你轻松地画出更漂亮的图形。而 Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
- 安装 pip3 install seaborn
- seaborn.lmplot() 是一个非常有用的方法,它会在绘制二维散点图时,自动完成回归拟合
- sns.lmplot() 里的 x, y 分别代表横纵坐标的列名,
- data= 是关联到数据集,
- hue=*代表按照 species 即花的类别分类显示,
- fit_reg=是否进行线性拟合。
- 参考链接:API 链接
# 内嵌绘图
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False
# 把数据转换成 dataframe 的格式
iris_d = pd.DataFrame(iris['data'], columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_d['Species'] = iris.target
# Petal_Width 花瓣宽度
# Sepal_Length 萼片长度
sns.relplot(x='Petal_Width', y='Sepal_Length', hue="Species", data=iris_d)
plt.show()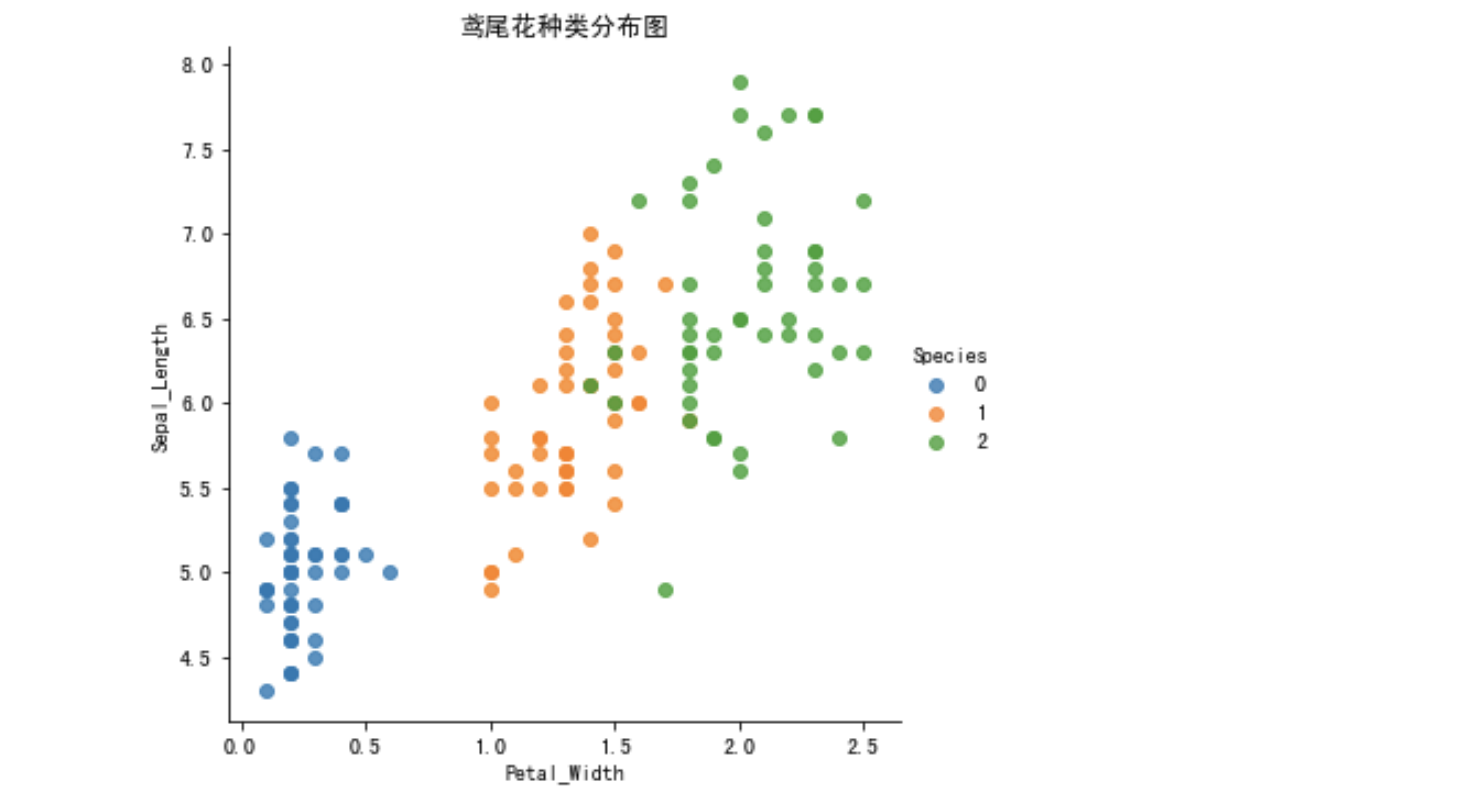
数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 25%
数据集划分 API
sklearn.model_selection.train_test_split(arrays, *options)
- 参数:
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为 float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return
- x_train, x_test, y_train, y_test
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1、获取鸢尾花数据集
iris = load_iris()
# 对鸢尾花数据集进行分割
# 训练集的特征值 x_train 测试集的特征值 x_test
# 训练集的目标值 y_train 测试集的目标值 y_test
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果随机数种子不一致:\n", (x_train != x_train1).sum())
print("如果随机数种子一致:\n", (x_train1 != x_train2).sum())流程实现
K-近邻算法 API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:
- int,可选(默认= 5),k_neighbors 查询默认使用的邻居数
- algorithm:
{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’}- 快速 k 近邻搜索算法,默认参数为 auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法 ball_tree、kd_tree、brute 方法进行搜索,
- brute 是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。
- kd_tree,构造 kd 树存储数据以便对其进行快速检索的树形数据结构,kd 树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于 20 时效率高。
- ball tree 是为了克服 kd 树高维失效而发明的,其构造过程是以质心 C 和半径 r 分割样本空间,每个节点是一个超球体。
- 快速 k 近邻搜索算法,默认参数为 auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法 ball_tree、kd_tree、brute 方法进行搜索,
数据集介绍
Iris 数据集是常用的分类实验数据集,由 Fisher, 1936 收集整理。Iris 也称鸢尾花卉数据集,是一类多重变量分析的数据集。关于数据集的具体介绍:
实例数量:150(三个类各有 50 个)
属性数量:4(数值型,数值型,帮助预测的属性和类)
属性:
- sepal length 萼片长度 (厘米)
- sepal width 萼片宽度 (厘米)
- petal length 花瓣长度 (厘米)
- petal width 花瓣宽度 (厘米)
- class: .
- lris-Setosa 山鸢尾
- lris-Versicolour 变色鸢尾
- lris-Virginica 维吉尼亚鸢尾
步骤分析
- 获取数据集
- 数据基本处理
- 特征工程
- 机器学习 (模型训练)
- 模型评估
代码过程
- 导入模块
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier- 先从 sklearn 当中获取数据集,然后进行数据集的分割
# 1. 获取数据集
iris = load_iris()
# 2. 数据基本处理
# x_train,x_test,y_train,y_test
# 为训练集特征值、测试集特征值、训练集目标值、测试集目标值
x_train, x_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=22
)进行数据标准化
特征值的标准化
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)- 模型进行训练预测
# 4、机器学习 (模型训练)
estimator = KNeighborsClassifier(n_neighbors=9)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法 1:比对真实值和预测值
y_predict = estimator.predict(x_test)
print("预测结果为:\n", y_predict)
print("比对真实值和预测值:\n", y_predict == y_test)
# 方法 2:直接计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)交叉验证,网格搜索
交叉验证 (cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成 4 份,其中一份作为验证集。然后经过 4 次 (组) 的测试,每次都更换不同的验证集。即得到 4 组模型的结果,取平均值作为最终结果。又称 4 折交叉验证。
我们之前知道数据分为训练集和测试集,但是**为了让从训练得到模型结果更加准确。**做以下处理
- 训练集:训练集 + 验证集
- 测试集:测试集

为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
问题:这个只是让被评估的模型更加准确可信,那么怎么选择或者调优参数呢?
什么是网格搜索 (Grid Search)
通常情况下,有很多参数是需要手动指定的(如 k-近邻算法中的 K 值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。 每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

交叉验证,网格搜索(模型选择与调优)API:
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}- cv:指定几个交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore__:在交叉验证中验证的最好结果
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
鸢尾花案例增加 K 值调优
- 使用 GridSearchCV 构建估计器
# 1、获取数据集
iris = load_iris()
# 2、数据基本处理 -- 划分数据集
x_train, x_test, y_train, y_test = train_test_split(
iris.data, iris.target, random_state=22
)
# 3、特征工程:标准化
# 实例化一个转换器类
transfer = StandardScaler()
# 调用 fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN 预估器流程
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 4.3 fit 数据进行训练
estimator.fit(x_train, y_train)
# 5、评估模型效果
# 方法 a:比对预测结果和真实值
y_predict = estimator.predict(x_test)
print("比对预测结果和真实值:\n", y_predict == y_test)
# 方法 b:直接计算准确率
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)- 然后进行评估查看最终选择的结果和交叉验证的结果
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)- 最终结果
比对预测结果和真实值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True True True True True True True True
True True]
直接计算准确率:
0.947368421053
在交叉验证中验证的最好结果:
0.973214285714
最好的参数模型:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
每次交叉验证后的准确率结果:
{'mean_fit_time': array([ 0.00114751, 0.00027037, 0.00024462]), 'std_fit_time': array([ 1.13901511e-03, 1.25300249e-05, 1.11011951e-05]), 'mean_score_time': array([ 0.00085751, 0.00048693, 0.00045625]), 'std_score_time': array([ 3.52785082e-04, 2.87650037e-05, 5.29673344e-06]), 'param_n_neighbors': masked_array(data = [1 3 5],
mask = [False False False],
fill_value = ?)
, 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}], 'split0_test_score': array([ 0.97368421, 0.97368421, 0.97368421]), 'split1_test_score': array([ 0.97297297, 0.97297297, 0.97297297]), 'split2_test_score': array([ 0.94594595, 0.89189189, 0.97297297]), 'mean_test_score': array([ 0.96428571, 0.94642857, 0.97321429]), 'std_test_score': array([ 0.01288472, 0.03830641, 0.00033675]), 'rank_test_score': array([2, 3, 1], dtype=int32), 'split0_train_score': array([ 1. , 0.95945946, 0.97297297]), 'split1_train_score': array([ 1. , 0.96 , 0.97333333]), 'split2_train_score': array([ 1. , 0.96, 0.96]), 'mean_train_score': array([ 1. , 0.95981982, 0.96876877]), 'std_train_score': array([ 0. , 0.00025481, 0.0062022 ])}