Transformer 网络结构
自 2017 年 Google 推出 Transformer 以来,基于其架构的语言模型便如雨后春笋般涌现,其中 Bert、T5 等备受瞩目,而近期风靡全球的大模型 ChatGPT 和 LLaMa 更是大放异彩。本节内容将 为大家深入解析 Transformer 的技术内核。
自然语言处理概述
自然语言处理(Nature language Processing, NLP)研究的主要是通过计算机算法来理解自然语言。对于自然语言来说,处理的数据主要就是人类的语言,例如:汉语、英语、法语等,该类型的数据不像我们前面接触的过的结构化数据、或者图像数据可以很方便的进行数值化。
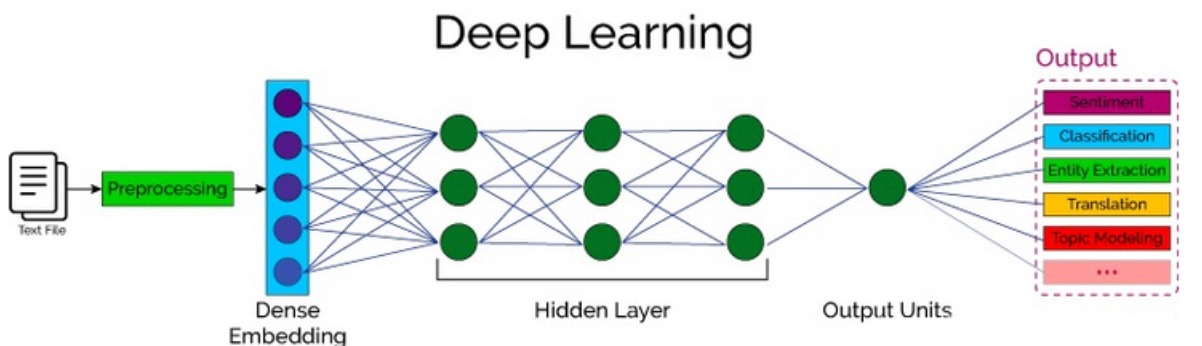
Transformer 整体结构
Transformer 是谷歌在 2017 年的论文《Attention Is All You Need》中提出的的用于机器翻译的模型。

Transformer 的内部,在本质上是一个 Encoder-Decoder 的结构,即 编码器 - 解码器
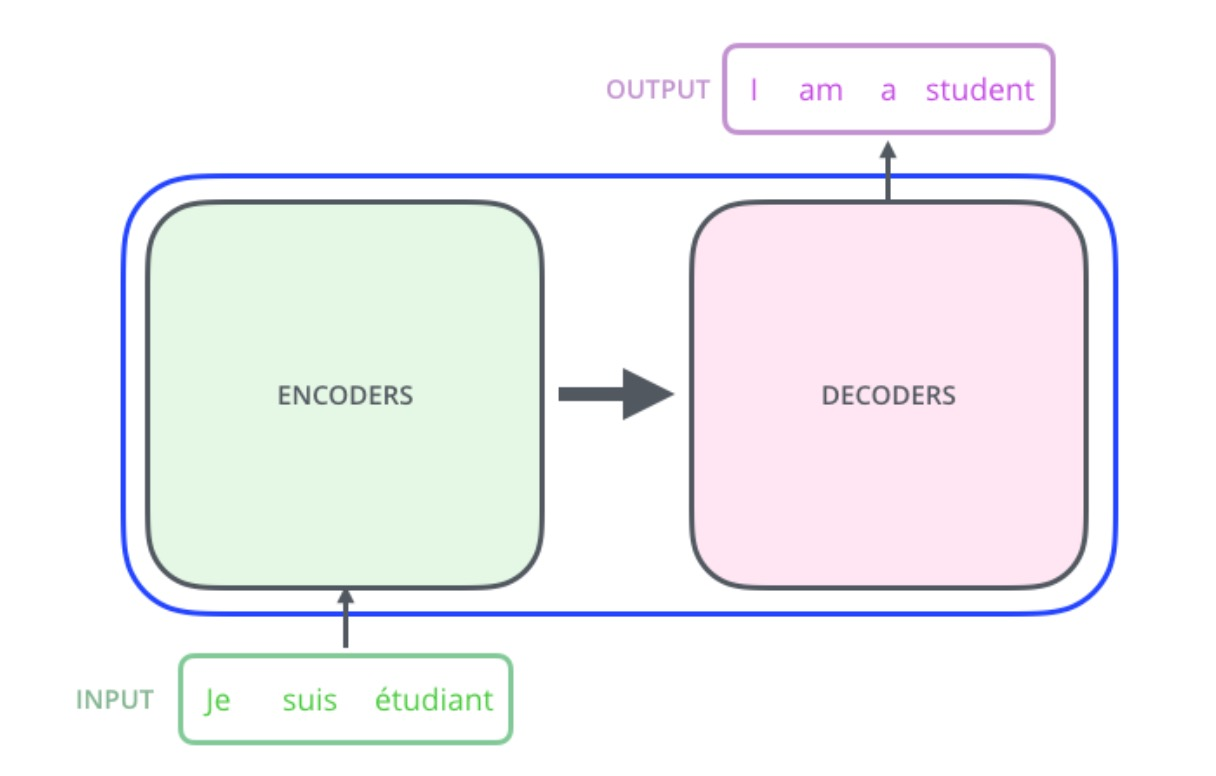
Transformer 的详细结构如右图所示,主要包括
以下内容:
输入部分
输出部分
编码器部分
解码器部分
Huggingface 的使用
Huggingface 是一家专注于自然语言处理、人工智能和分布式系统的创业公司。Huggingface 一直致力于自然语言处理 NLP 技术的平民化 (democratize),希望每个人都能用上最先进 (SOTA, state-of-the-art) 的 NLP 技术。

国内镜像站:https://hf-mirror.com/
Huggingface Transformers 是基于一个开源基于 transformer 模型结构提供的预训练语言库。它支持 Pytorch,Tensorflow2.0,并且支持两个框架的相互转换。Transformers 提供了 NLP 领域大量 state-of-art 的 预训练语言模型结构的模型和调用框架。
Transformer 库的使用
Transformers 库提供了很多 SOTA 的预训练模型,比如 BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, CTRL。它的安装方式如下所示:
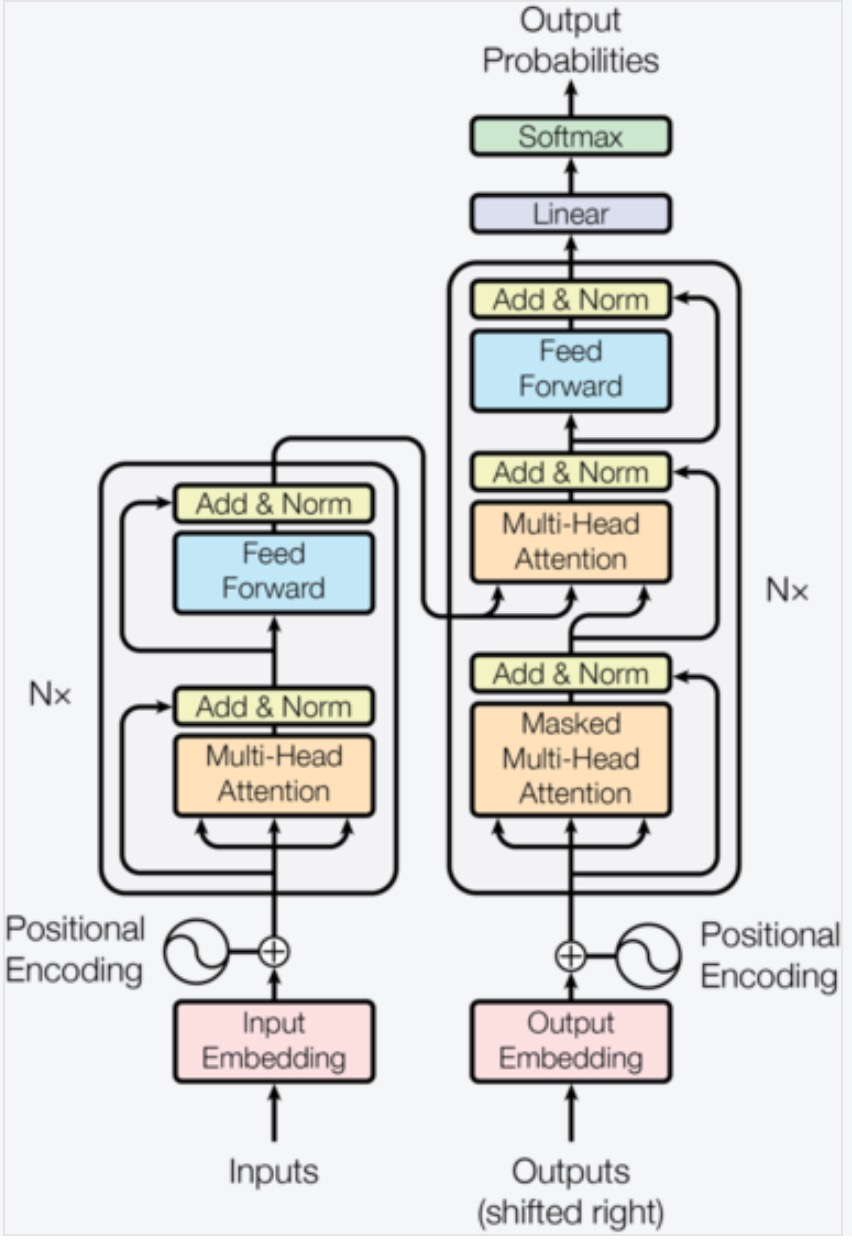
pip install TransformersTransformers 库三层应用结构如右图所示:
- 管道(Pipline):高度集成的极简使用方式,只需要几行代码即可实现一个 NLP 任务。
- 自动模型(AutoMode):可载入并使用 BERTology 系列模型。
- 具体模型(SpecificModel):使用时,明 确指定具体的模型,并按照每个 BERTology 系列模型中的特定参数进行调用,该方式相对复杂,但具有较高的灵活度。
汉译英的实现
在这里我们利用 huggingface 中应用来实现汉译英,链接如下所示:
https://huggingface.co/liam168/trans-opus-mt-zh-en
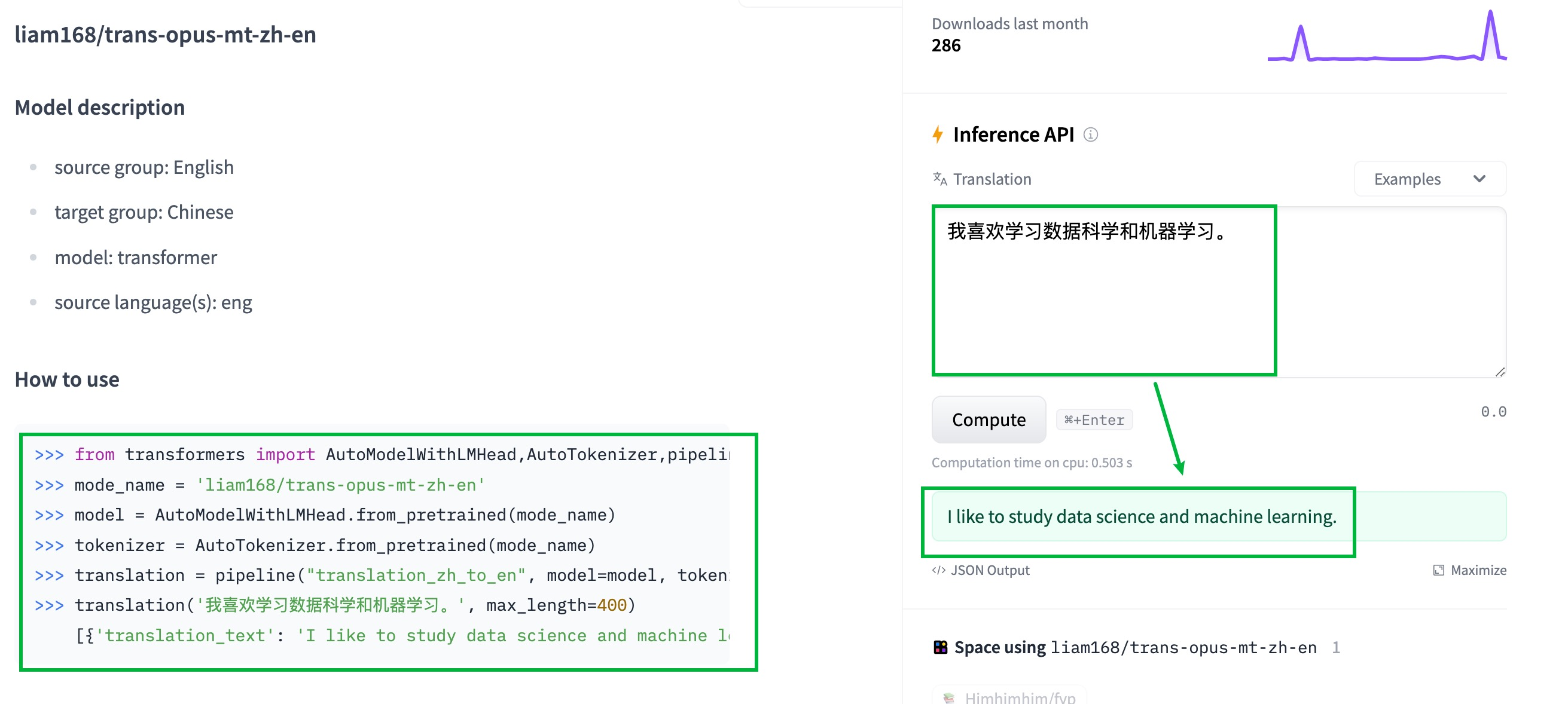
# 导入工具包
from transformers import AutoModelWithLMHead, AutoTokenizer, pipeline
# 指明预训练模型
mode_name = 'liam168/trans-opus-mt-zh-en'
# 加载预训练模型
model = AutoModelWithLMHead.from_pretrained(mode_name)
# 加载词嵌入层
tokenizer = AutoTokenizer.from_pretrained(mode_name)
# 使用管道的方式进行机器翻译
translation = pipeline("translation_zh_to_en", model=model, tokenizer=tokenizer)
# 将要翻译的文本传递到 API 中
out = translation('我喜欢学习数据科学和机器学习。', max_length=400)
# 输出结果
print(out)[{'translation_text': 'I like to study data science and machine learning.'}]总结:
- 自然语言处理是通过计算机算法来理解自然语言
- Transformer 由编码器和解码器构成
- 利用 huggingFace 完成汉译英任务