欠拟合和过拟合
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在测试数据集上却不能很好地拟合数据 ,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据 ,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
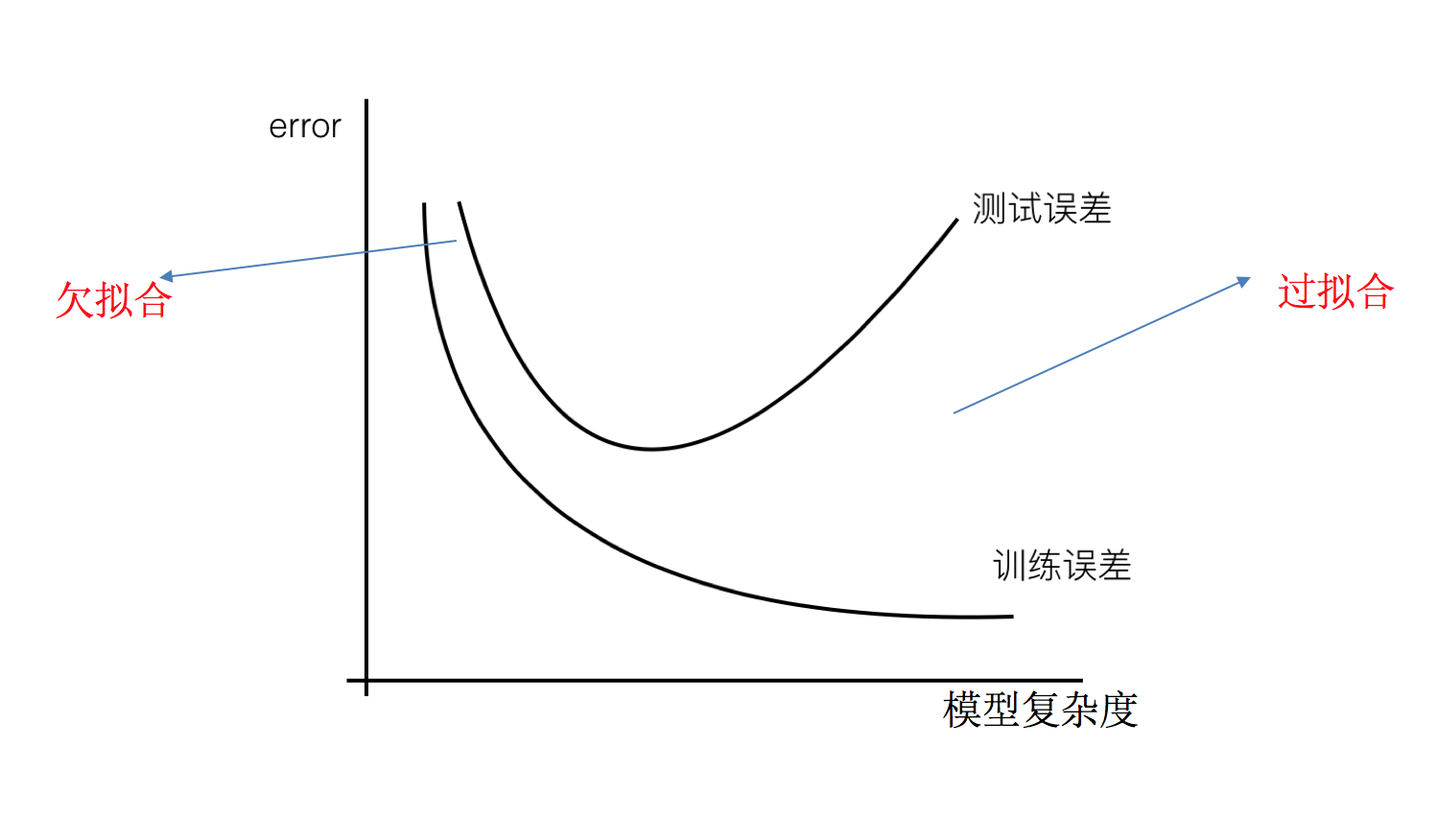
那么是什么原因导致模型复杂?线性回归进行训练学习的时候变成模型会变得复杂,这里就对应前面再说的线性回归的两种关系,非线性关系的数据,也就是存在很多无用的特征或者现实中的事物特征跟目标值的关系并不是简单的线性关系。
原因以及解决办法
欠拟合原因以及解决办法
- 原因:学习到数据的特征过少
- 解决办法:
- 1)添加其他特征项, 有时候我们模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段,无论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。除上面的特征之外,“上下文特征”、“平台特征”等等,都可以作为特征添加的首选项。
- 2)添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
过拟合原因以及解决办法
- 原因:原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点
- 解决办法:
- 1)重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
- 2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
- 3)正则化
- 4)减少特征维度,防止维灾难
正则化
什么是正则化
在解决回归过拟合中,我们选择正则化。但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树、神经网络),我们更多的也是去自己做特征选择,包括之前说的删除、合并一些特征
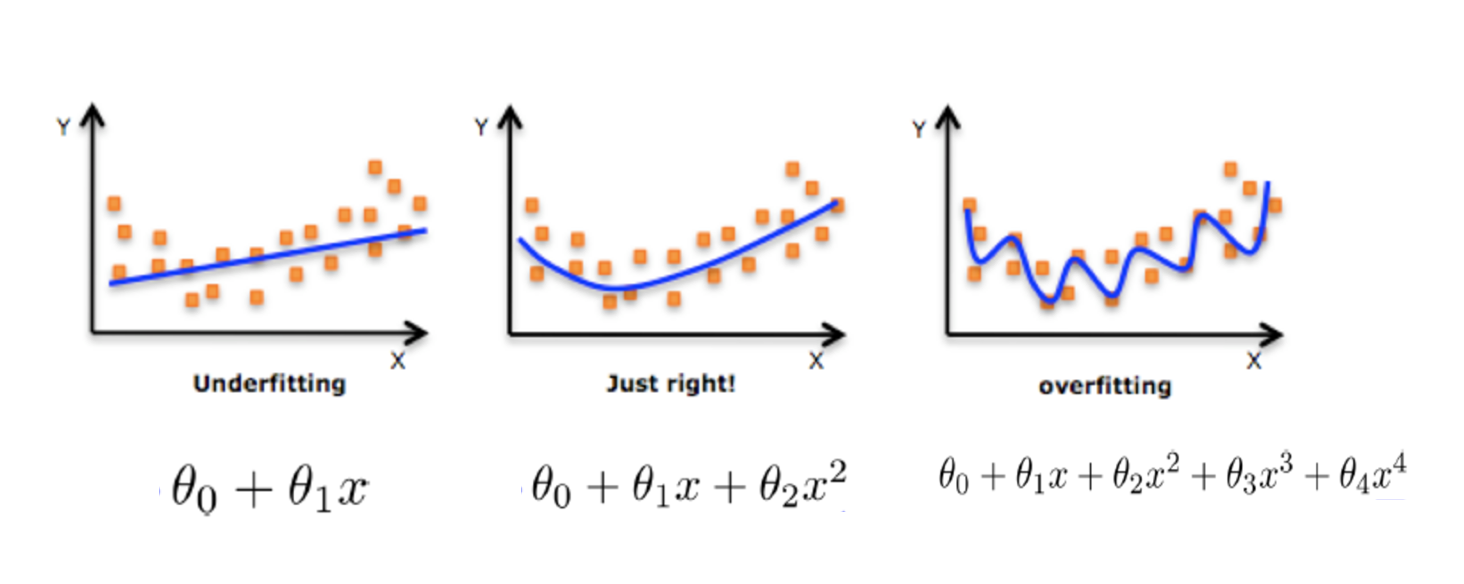
如何解决?

**在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化 **
注:调整时候,算法并不知道某个特征影响,而是去调整参数得出优化的结果
正则化类别
- L2 正则化
- 作用:可以使得其中一些 W 的都很小,都接近于 0,削弱某个特征的影响
- 优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
- Ridge 回归
- L1 正则化
- 作用:可以使得其中一些 W 的值直接为 0,删除这个特征的影响
- LASSO 回归
小结
- 欠拟合【掌握】
- 在训练集上表现不好,在测试集上表现不好
- 解决方法:
- 继续学习
- 添加其他特征项
- 添加多项式特征
- 继续学习
- 过拟合【掌握】
- 在训练集上表现好,在测试集上表现不好
- 解决方法:
- 重新清洗数据集
- 增大数据的训练量
- 正则化
- 减少特征维度
- 正则化【掌握】
- 通过限制高次项的系数进行防止过拟合
- L1 正则化
- 理解:直接把高次项前面的系数变为 0
- Lasso 回归
- L2 正则化
- 理解:把高次项前面的系数变成特别小的值
- 岭回归
正则化线性模型
- Ridge Regression 岭回归 -Lasso 回归 -Elastic Net 弹性网络 -Early stopping
岭回归
Ridge Regression (岭回归,又名 Tikhonov regularization)
岭回归是线性回归的正则化版本,即在原来的线性回归的 cost function 中添加正则项(regularization term): 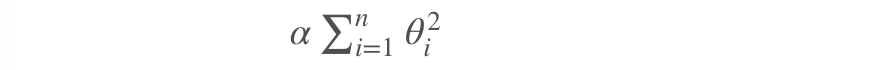
以达到在拟合数据的同时,使模型权重尽可能小的目的,岭回归代价函数:
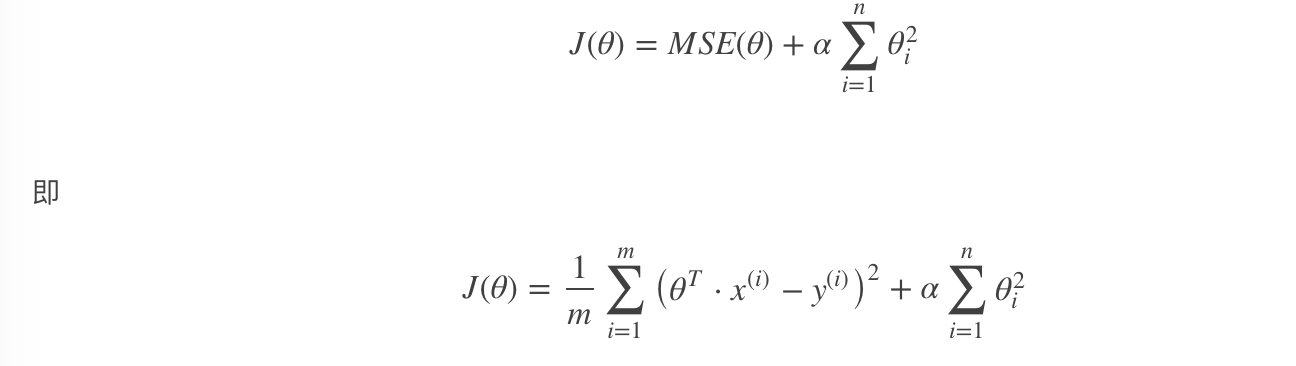
- α=0:岭回归退化为线性回归
Lasso 回归
Lasso Regression(Lasso 回归)
Lasso 回归是线性回归的另一种正则化版本,正则项为权值向量的ℓ1 范数。
Lasso 回归的代价函数:
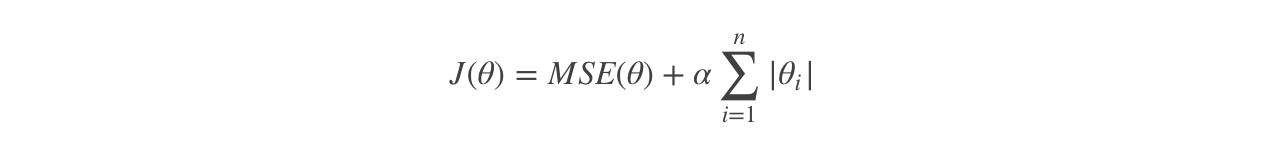
【注意】
- Lasso Regression 的代价函数在 θi=0 处是不可导的 .
- 解决方法:在θi=0 处用一个次梯度向量 (subgradient vector) 代替梯度,如下式
- Lasso Regression 的次梯度向量

Lasso Regression 有一个很重要的性质是:倾向于完全消除不重要的权重。
例如:当α 取值相对较大时,高阶多项式退化为二次甚至是线性:高阶多项式特征的权重被置为 0。
也就是说,Lasso Regression 能够自动进行特征选择,并输出一个稀疏模型(只有少数特征的权重是非零的)。
Elastic Net (弹性网络)
弹性网络在岭回归和 Lasso 回归中进行了折中,通过 混合比 (mix ratio) r 进行控制:
- r=0:弹性网络变为岭回归
- r=1:弹性网络便为 Lasso 回归
一般来说,我们应避免使用朴素线性回归,而应对模型进行一定的正则化处理,那如何选择正则化方法呢?
小结:
常用:岭回归
假设只有少部分特征是有用的:
- 弹性网络
- Lasso
- 一般来说,弹性网络的使用更为广泛。因为在特征维度高于训练样本数,或者特征是强相关的情况下,Lasso 回归的表现不太稳定。
api:
pythonfrom sklearn.linear_model import Ridge, ElasticNet, Lasso
Early Stopping [了解]
Early Stopping 也是正则化迭代学习的方法之一。
其做法为:在验证错误率达到最小值的时候停止训练。
小结
- Ridge Regression 岭回归
- 就是把系数添加平方项
- 然后限制系数值的大小
- α值越小,系数值越大,α越大,系数值越小
- Lasso 回归
- 对系数值进行绝对值处理
- 由于绝对值在顶点处不可导,所以进行计算的过程中产生很多 0,最后得到结果为:稀疏矩阵
- Elastic Net 弹性网络
- 是前两个内容的综合
- 设置了一个 r,如果 r=0--岭回归;r=1--Lasso 回归
- Early stopping
- 通过限制错误率的阈值,进行停止