字典特征提取
作用:对字典数据进行特征值化
- sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- DictVectorizer.fit_transform(X)
- X:字典或者包含字典的迭代器返回值
- 返回 sparse 矩阵
- DictVectorizer.get_feature_names() 返回类别名称
- DictVectorizer.fit_transform(X)
我们对以下数据进行特征提取
json
[
{
"city": "北京",
"temperature": 100
},
{
"city": "上海",
"temperature": 60
},
{
"city": "深圳",
"temperature": 30
}
]
流程分析
- 实例化类 DictVectorizer
- 调用 fit_transform 方法输入数据并转换(注意返回格式)
python
from sklearn.feature_extraction import DictVectorizer
"""
对字典类型的数据进行特征抽取
"""
data = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60}, {'city': '深圳', 'temperature': 30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=False)
# 2、调用 fit_transform
data = transfer.fit_transform(data)
print("返回的结果:\n", data)
# 打印特征名字
print("特征名字:\n", transfer.get_feature_names())注意观察没有加上 sparse=False 参数的结果
返回的结果:
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
特征名字:
['city=上海', 'city=北京', 'city=深圳', 'temperature']这个结果并不是我们想要看到的,所以加上参数,得到想要的结果:
返回的结果:
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
特征名字:
['city=上海', 'city=北京', 'city=深圳', 'temperature']之前在 pandas 中的离散化,也实现了类似的效果。
我们把这个处理数据的技巧叫做”one-hot“编码:
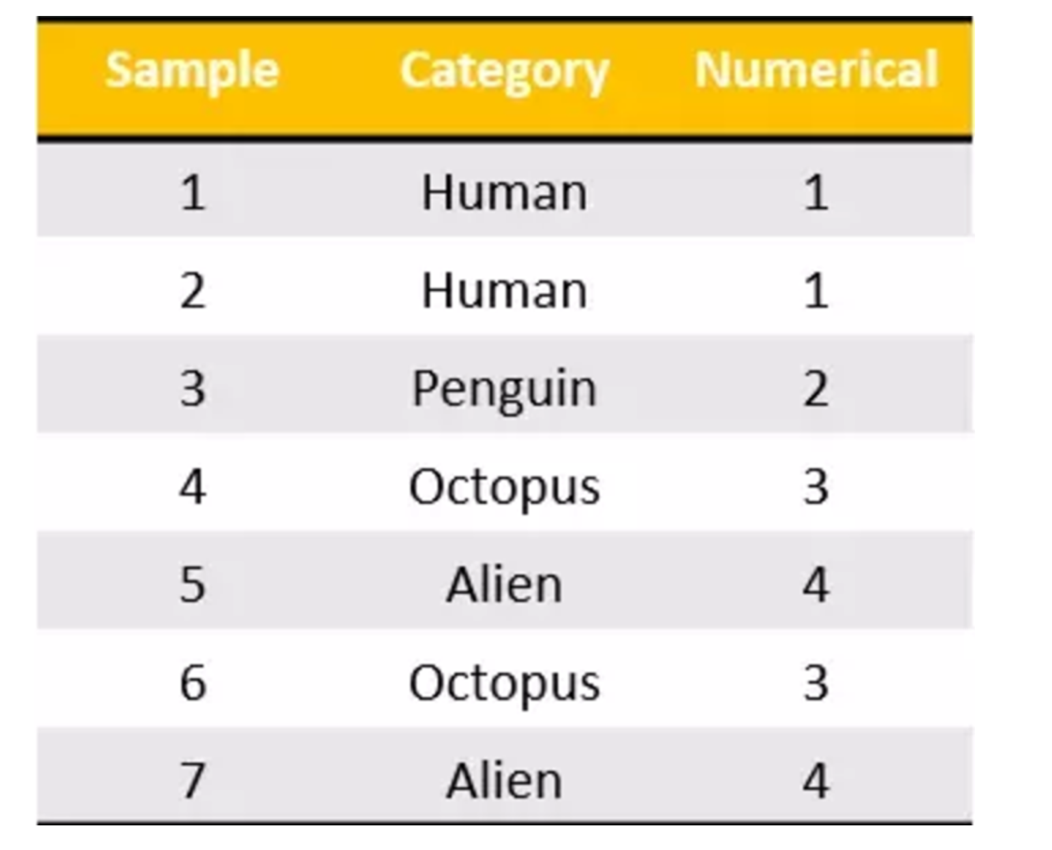
转化为:
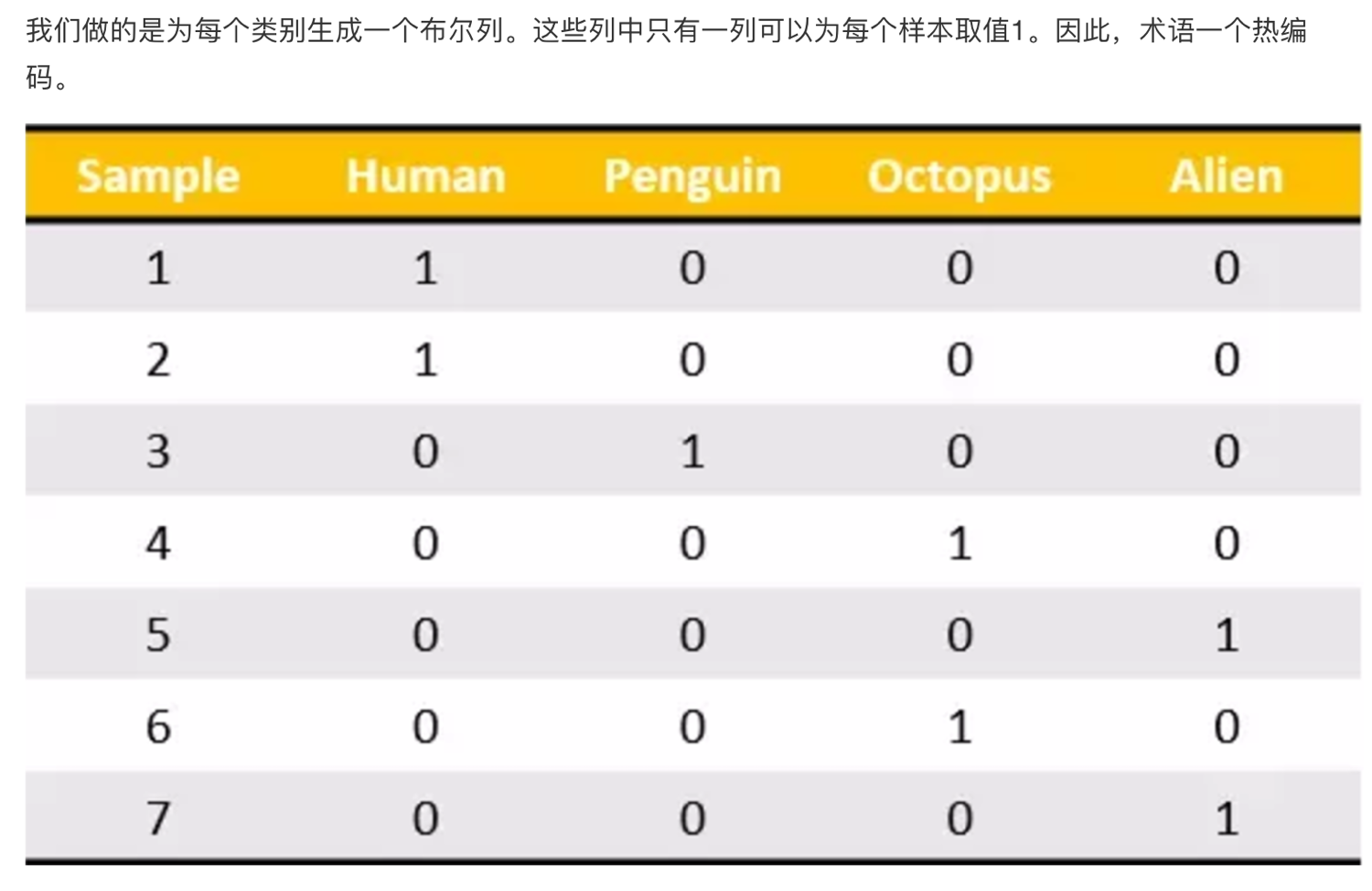
总结
对于特征当中存在类别信息的我们都会做 one-hot 编码处理
- 字典特征提取【知道】
- 字典特征提取就是对类别型数据进行转换
- api:sklearn.feature_extraction.DictVectorizer(sparse=True,…)
- aparse 矩阵
- 1.节省内容
- 2.提高读取效率
- 注意:
- 对于特征当中存在类别信息的我们都会做 one-hot 编码处理
- aparse 矩阵