特征工程
什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 意义:会直接影响机器学习的效果
为什么需要特征工程 (Feature Engineering)
机器学习领域的大神 Andrew Ng(吴恩达) 老师说“Coming up with features is difficult, time-consuming, requires expert knowledge. "Applied machine learning" is basically feature engineering. "
注:业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征工程包含内容
- 特征提取
- 特征预处理
- 特征降维
各概念具体解释
特征提取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征

特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
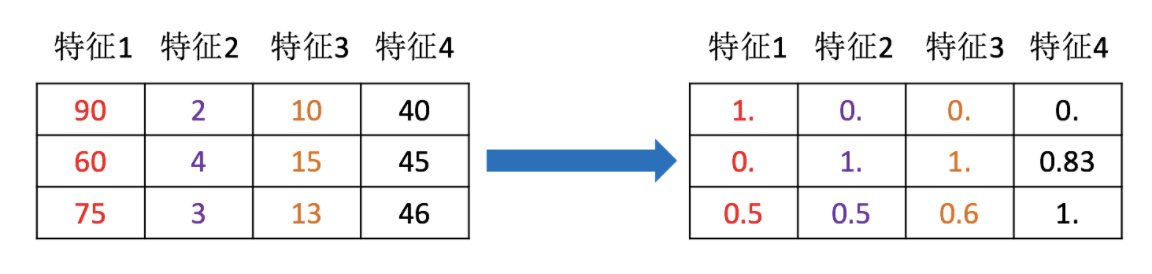
特征降维
指在某些限定条件下,降低随机变量 (特征) 个数,得到一组“不相关”主变量的过程
特征预处理
特征预处理定义
scikit-learn 的解释
provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.
翻译过来:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
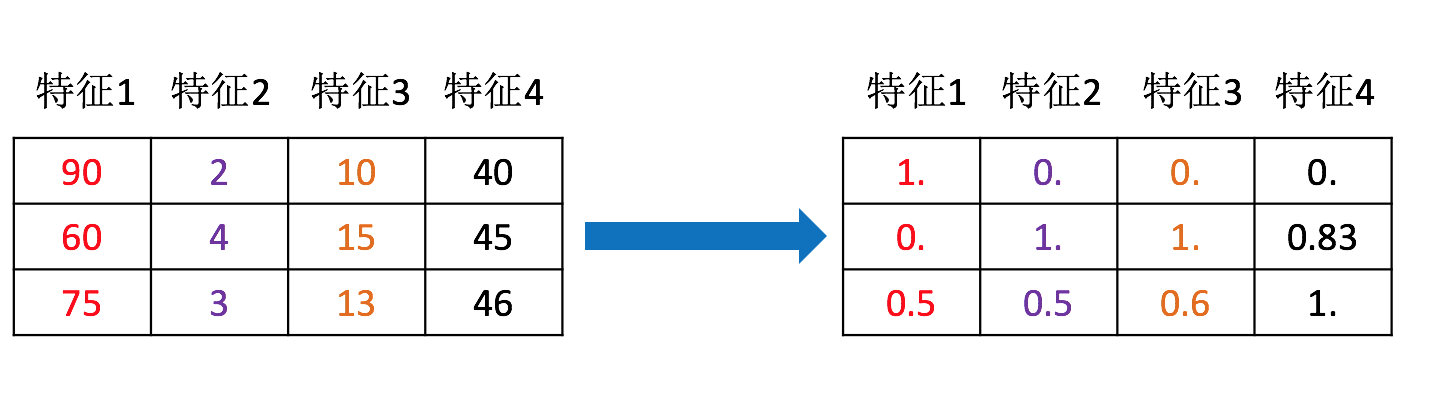
为什么我们要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果 ,使得一些算法无法学习到其它的特征
举例:约会对象数据
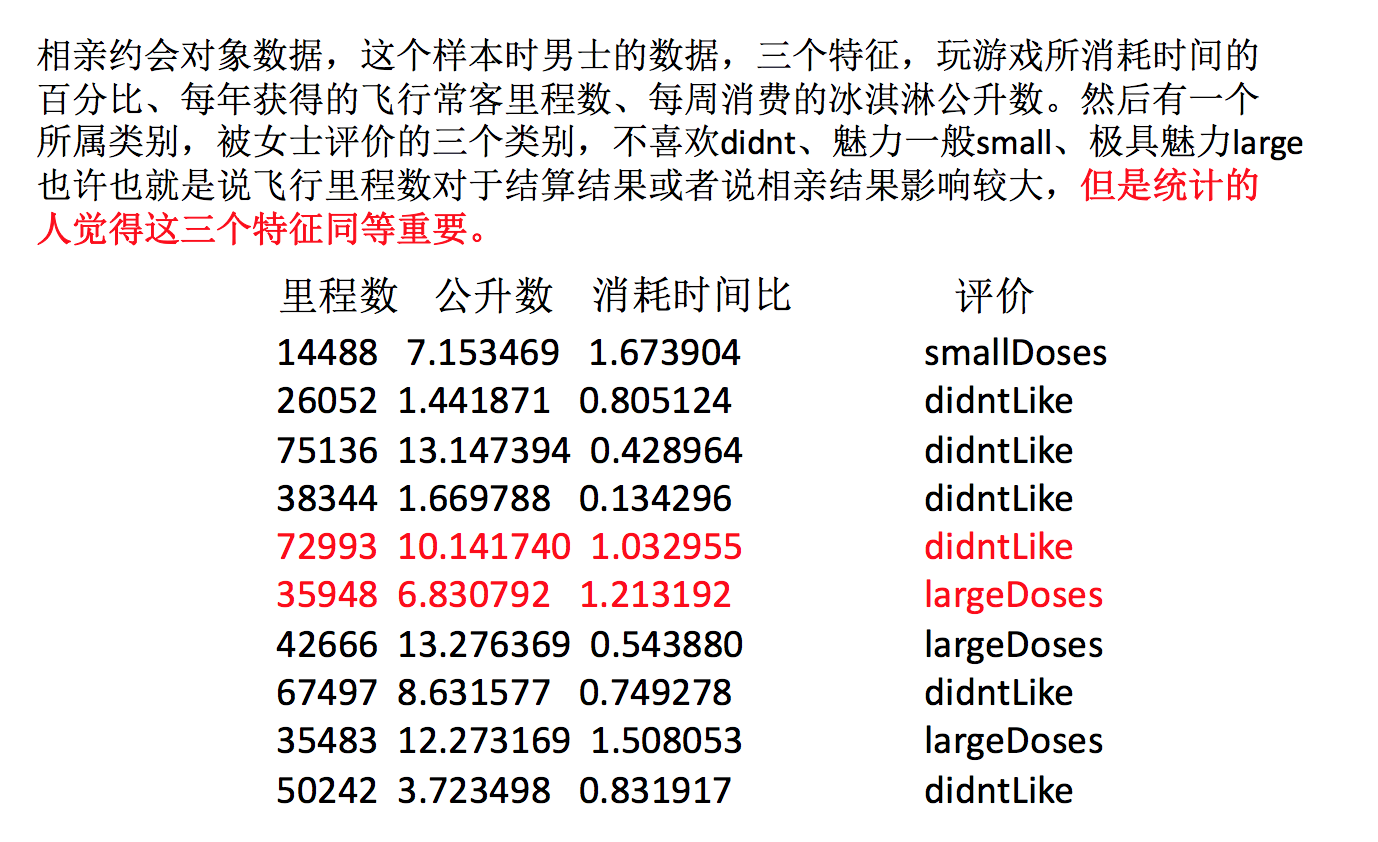
我们需要用到一些方法进行无量纲化,使不同规格的数据转换到同一规格
特征预处理
- 归一化
- 标准化
处理 api
sklearn.preprocessing归一化
定义
通过对原始数据进行变换把数据映射到 (默认为 [0,1]) 之间
公式
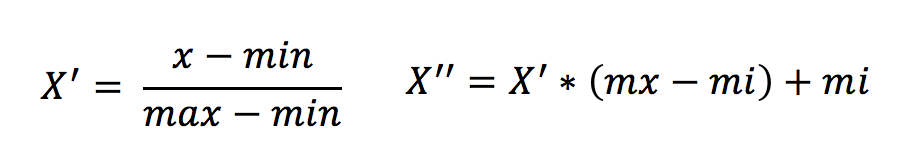
作用于每一列,max 为一列的最大值,min 为一列的最小值,那么 X’’为最终结果,mx,mi 分别为指定区间值默认 mx 为 1,mi 为 0
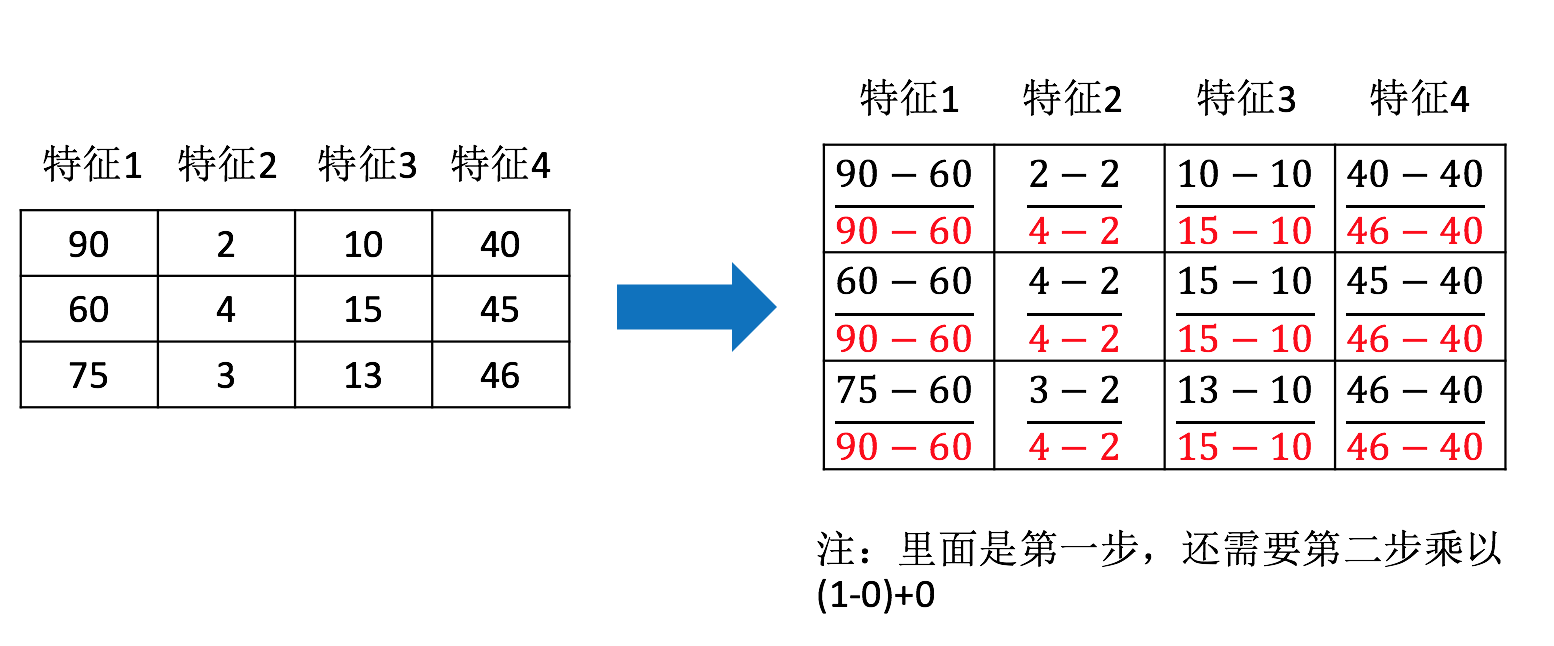
那么怎么理解这个过程呢?我们通过一个例子
API
sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
- MinMaxScalar.fit_transform(X)
- X:numpy array 格式的数据 [n_samples,n_features]
- 返回值:转换后的形状相同的 array
数据计算
我们对以下数据进行运算,在 dating.txt 中。保存的就是之前的约会对象数据
milage, Liters, Consumtime, target
40920, 8.326976, 0.953952, 3
14488, 7.153469, 1.673904, 2
26052, 1.441871, 0.805124, 1
75136, 13.147394, 0.428964, 1
38344, 1.669788, 0.134296, 1- 分析
1、实例化 MinMaxScalar
2、通过 fit_transform 转换
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
"""归一化演示"""
data = pd.read_csv("dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = MinMaxScaler(feature_range=(2, 3))
# 2、调用 fit_transform
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print("最小值最大值归一化处理的结果:\n", data)返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
3 75136 13.147394 0.428964 1
..............
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
最小值最大值归一化处理的结果:
[[2.44832535 2.39805139 2.56233353]
[2.15873259 2.34195467 2.98724416]
[2.28542943 2.06892523 2.47449629]
...,
[2.29115949 2.50910294 2.51079493]
[2.52711097 2.43665451 2.4290048]
[2.47940793 2.3768091 2.78571804]]问题:如果数据中异常点较多,会有什么影响?
归一化总结
注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
怎么办?
标准化
定义
通过对原始数据进行变换把数据变换到均值为 0,标准差为 1 范围内
公式
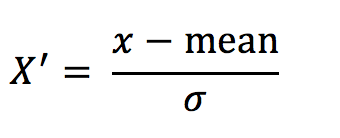
作用于每一列,mean 为平均值,σ为标准差
所以回到刚才异常点的地方,我们再来看看标准化
- 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
- 对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
API
sklearn.preprocessing.StandardScaler()
- 处理之后每列来说所有数据都聚集在均值 0 附近标准差差为 1
- StandardScaler.fit_transform(X)
- X:numpy array 格式的数据
[n_samples,n_features]
- X:numpy array 格式的数据
- 返回值:转换后的形状相同的 array
数据计算
同样对上面的数据进行处理
1、实例化 StandardScaler
2、通过 fit_transform 转换
import pandas as pd
from sklearn.preprocessing import StandardScaler
"""标准化演示"""
data = pd.read_csv("dating.txt")
print(data)
# 1、实例化一个转换器类
transfer = StandardScaler()
# 2、调用 fit_transform
data = transfer.fit_transform(data[['milage', 'Liters', 'Consumtime']])
print("标准化的结果:\n", data)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)返回结果:
milage Liters Consumtime target
0 40920 8.326976 0.953952 3
1 14488 7.153469 1.673904 2
2 26052 1.441871 0.805124 1
... ... ... ... ...
997 26575 10.650102 0.866627 3
998 48111 9.134528 0.728045 3
999 43757 7.882601 1.332446 3
[1000 rows x 4 columns]
标准化的结果:
[[0.33193158 0.41660188 0.24523407]
[ -0.87247784 0.13992897 1.69385734]
[-0.34554872 - 1.20667094 -0.05422437]
...,
[-0.32171752 0.96431572 0.06952649]
[0.65959911 0.60699509 -0.20931587]
[0.46120328 0.31183342 1.00680598]]
每一列特征的平均值:
[3.36354210e+04 6.55996083e+00 8.32072997e-01]
每一列特征的方差:
[4.81628039e+08 1.79902874e+01 2.46999554e-01]标准化总结
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。什么是 TF-IDF 值呢?
我在多项式朴素贝叶斯中提到了“词的 TF-IDF 值”,如何理解这个概念呢?
TF-IDF 是一个统计方法,用来评估某个词语对于一个文件集或文档库中的其中一份文件的重要程度。
TF-IDF 实际上是两个词组 Term Frequency 和 Inverse Document Frequency 的总称,两者缩写为 TF 和 IDF,分别代表了词频和逆向文档频率。
词频 TF计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。
逆向文档频率 IDF,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF 越大就代表该单词的区分度越大。
所以 TF-IDF 实际上是词频 TF 和逆向文档频率 IDF 的乘积 。这样我们倾向于找到 TF 和 IDF 取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。
TF-IDF
TF-IDF 如何计算?首先我们看下词频 TF 和逆向文档概率 IDF 的公式。
为什么 IDF 的分母中,单词出现的文档数要加 1 呢?因为有些单词可能不会存在文档中,为了避免分母为 0,统一给单词出现的文档数都加 1。
你可以看到,TF-IDF 值就是 TF 与 IDF 的乘积,这样可以更准确地对文档进行分类。比如“我”这样的高频单词,虽然 TF 词频高,但是 IDF 值很低,整体的 TF-IDF 也不高。
我在这里举个例子。假设一个文件夹里一共有 10 篇文档,其中一篇文档有 1000 个单词,“this”这个单词出现 20 次,“bayes”出现了 5 次。“this”在所有文档中均出现过,而“bayes”只在 2 篇文档中出现过。我们来计算一下这两个词语的 TF-IDF 值。
针对“this”,计算 TF-IDF 值:
所以 TF-IDF=0.02*(-0.0414)=-8.28e-4。
针对“bayes”,计算 TF-IDF 值:
TF-IDF=0.005*0.5229=2.61e-3.
很明显“bayes”的 TF-IDF 值要大于“this”的 TF-IDF 值。这就说明用“bayes”这个单词做区分比单词“this”要好。
如何求 TF-IDF
在 sklearn 中我们直接使用 TfidfVectorizer 类,它可以帮我们计算单词 TF-IDF 向量的值。在这个类中,取 sklearn 计算的对数 log 时,底数是 e,不是 10。
下面我来讲下如何创建 TfidfVectorizer 类。
TfidfVectorizer
创建 TfidfVectorizer 的方法是:
TfidfVectorizer(stop_words=stop_words, token_pattern=token_pattern)我们在创建的时候,有两个构造参数,可以自定义停用词 stop_words 和规律规则 token_pattern。需要注意的是传递的数据结构,停用词 stop_words 是一个列表 List 类型,而过滤规则 token_pattern 是正则表达式。
什么是停用词?停用词就是在分类中没有用的词,这些词一般词频 TF 高,但是 IDF 很低,起不到分类的作用。为了节省空间和计算时间,我们把这些词作为停用词 stop words,告诉机器这些词不需要帮我计算。

当我们创建好 TF-IDF 向量类型时,可以用 fit_transform 帮我们计算,返回给我们文本矩阵,该矩阵表示了每个单词在每个文档中的 TF-IDF 值。

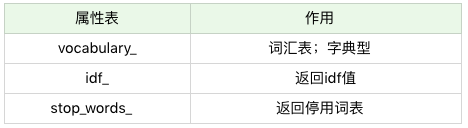
在我们进行 fit_transform 拟合模型后,我们可以得到更多的 TF-IDF 向量属性,比如,我们可以得到词汇的对应关系(字典类型) 和向量的 IDF 值,当然也可以获取设置的停用词 stop_words。
举个例子,假设我们有 4 个文档:
文档 1:this is the bayes document;
文档 2:this is the second second document;
文档 3:and the third one;
文档 4:is this the document。
现在想要计算文档里都有哪些单词,这些单词在不同文档中的 TF-IDF 值是多少呢?
首先我们创建 TfidfVectorizer 类:
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer()然后我们创建 4 个文档的列表 documents,并让创建好的 tfidf_vec 对 documents 进行拟合,得到 TF-IDF 矩阵:
documents = [
'this is the bayes document',
'this is the second second document',
'and the third one',
'is this the document'
]
tfidf_matrix = tfidf_vec.fit_transform(documents)输出文档中所有不重复的词:
print('不重复的词:', tfidf_vec.get_feature_names())运行结果
不重复的词: ['and', 'bayes', 'document', 'is', 'one', 'second', 'the', 'third', 'this']输出每个单词对应的 id 值:
print('每个单词的ID:', tfidf_vec.vocabulary_)运行结果
每个单词的ID: {'this': 8, 'is': 3, 'the': 6, 'bayes': 1, 'document': 2, 'second': 5, 'and': 0, 'third': 7, 'one': 4}输出每个单词在每个文档中的 TF-IDF 值,向量里的顺序是按照词语的 id 顺序来的:
print('每个单词的tfidf值:', tfidf_matrix.toarray())运行结果:
每个单词的tfidf值: [[0. 0.63314609 0.40412895 0.40412895 0. 0.
0.33040189 0. 0.40412895]
[0. 0. 0.27230147 0.27230147 0. 0.85322574
0.22262429 0. 0.27230147]
[0.55280532 0. 0. 0. 0.55280532 0.
0.28847675 0.55280532 0. ]
[0. 0. 0.52210862 0.52210862 0. 0.
0.42685801 0. 0.52210862]]